Esta guía es para usuarios actuales de ClickHouse Cloud. Si eres nuevo en ClickHouse Cloud, te recomendamos nuestra guía de Primeros pasos para Managed ClickStack.
En este patrón de implementación, tanto ClickHouse como la UI de ClickStack (HyperDX) se alojan en ClickHouse Cloud, lo que minimiza la cantidad de componentes que el usuario necesita alojar por su cuenta.
Además de reducir la gestión de la infraestructura, este patrón de implementación garantiza que la autenticación esté integrada con el SSO/SAML de ClickHouse Cloud. A diferencia de las implementaciones autohospedadas, tampoco es necesario aprovisionar una instancia de MongoDB para almacenar el estado de la aplicación, como dashboards, búsquedas guardadas, configuraciones de usuario y alertas. Los usuarios también se benefician de:
- Escalado automático de la capacidad de cómputo independiente del almacenamiento
- Retención de bajo costo y prácticamente ilimitada basada en almacenamiento de objetos
- La capacidad de aislar de forma independiente las cargas de trabajo de lectura y escritura con Warehouses.
- Autenticación integrada
- Copias de seguridad automatizadas
- Funciones de seguridad y cumplimiento
- Actualizaciones sin complicaciones
En este modo, la ingestión de datos queda completamente en manos del usuario. Puedes ingestar datos en Managed ClickStack usando tu propio OpenTelemetry Collector alojado, ingestión directa desde bibliotecas cliente, motores de tabla nativos de ClickHouse (como Kafka o S3), canalizaciones ETL o ClickPipes, el servicio gestionado de ingestión de ClickHouse Cloud. Este enfoque ofrece la forma más sencilla y de mayor rendimiento de operar ClickStack.
Este patrón de implementación es ideal para los siguientes escenarios:
- Ya tienes datos de observabilidad en ClickHouse Cloud y deseas visualizarlos con ClickStack.
- Operas una implementación de observabilidad a gran escala y necesitas el rendimiento y la escalabilidad dedicados de ClickStack en ClickHouse Cloud.
- Ya usas ClickHouse Cloud para analítica y quieres instrumentar tu aplicación con las bibliotecas de instrumentación de ClickStack, enviando los datos al mismo clúster. En este caso, recomendamos usar warehouses para aislar la capacidad de cómputo de las cargas de trabajo de observabilidad.
La siguiente guía asume que ya has creado un servicio de ClickHouse Cloud. Si aún no has creado uno, sigue la guía de Primeros pasos para Managed ClickStack. Así tendrás un servicio en el mismo estado que el de esta guía; es decir, listo para recibir datos de observabilidad con ClickStack habilitado.
Crear un nuevo servicio
En la página principal de ClickHouse Cloud, selecciona New service para crear un nuevo servicio.Especifica el proveedor, la región y el recurso
Scale vs EnterpriseRecomendamos este nivel Scale para la mayoría de las cargas de trabajo de ClickStack. Elija el nivel Enterprise si necesita funciones de seguridad avanzadas, como SAML, CMEK o cumplimiento de HIPAA. También ofrece perfiles de hardware personalizados para implementaciones de ClickStack de gran tamaño. En estos casos, le recomendamos ponerse en contacto con el soporte.  Al seleccionar la CPU y la memoria, calcúlelas en función del throughput de ingestión esperado de ClickStack. La tabla siguiente ofrece una guía para dimensionar estos recursos.
Al seleccionar la CPU y la memoria, calcúlelas en función del throughput de ingestión esperado de ClickStack. La tabla siguiente ofrece una guía para dimensionar estos recursos.| Volumen mensual de ingestión | Capacidad de cómputo recomendada |
|---|
| < 10 TB / mes | 2 vCPU × 3 réplicas |
| 10–50 TB / mes | 4 vCPU × 3 réplicas |
| 50–100 TB / mes | 8 vCPU × 3 réplicas |
| 100–500 TB / mes | 30 vCPU × 3 réplicas |
| 1 PB+ / mes | 59 vCPU × 3 réplicas |
- El volumen de datos se refiere al volumen mensual de ingestión sin comprimir y se aplica tanto a logs como a traces.
- Los patrones de consulta son típicos de los casos de uso de observabilidad, y la mayoría de las consultas se centran en datos recientes, por lo general de las últimas 24 horas.
- La ingestión es relativamente uniforme a lo largo del mes. Si espera tráfico irregular o picos, debe aprovisionar capacidad adicional.
- El almacenamiento se gestiona por separado mediante object storage de ClickHouse Cloud y no es un factor limitante para la retención. Suponemos que a los datos retenidos durante periodos más largos se accede con poca frecuencia.
Puede que se necesite más capacidad de cómputo para patrones de acceso que consultan regularmente intervalos de tiempo más amplios, realizan agregaciones intensivas o dan soporte a un gran número de usuarios concurrentes.Aunque dos réplicas pueden cubrir los requisitos de CPU y memoria para un throughput de ingestión determinado, recomendamos usar tres réplicas siempre que sea posible para lograr la misma capacidad total y mejorar la redundancia del servicio.Estos valores son solo estimaciones y deben utilizarse como referencia inicial. Los requisitos reales dependen de la complejidad de las consultas, la concurrencia, las políticas de retención y la variación del throughput de ingestión. Supervise siempre el uso de recursos y escale según sea necesario.
Configura la ingestión
Una vez aprovisionado el servicio, asegúrate de que esté seleccionado y haz clic en “ClickStack” en el menú de la izquierda. Selecciona “Start Ingestion” y se te pedirá que elijas una fuente de ingestión. Managed ClickStack admite OpenTelemetry y Vector como principales fuentes de ingestión. Sin embargo, los usuarios también pueden enviar datos directamente a ClickHouse con su propio esquema mediante cualquiera de las integraciones compatibles con ClickHouse Cloud.
Selecciona “Start Ingestion” y se te pedirá que elijas una fuente de ingestión. Managed ClickStack admite OpenTelemetry y Vector como principales fuentes de ingestión. Sin embargo, los usuarios también pueden enviar datos directamente a ClickHouse con su propio esquema mediante cualquiera de las integraciones compatibles con ClickHouse Cloud.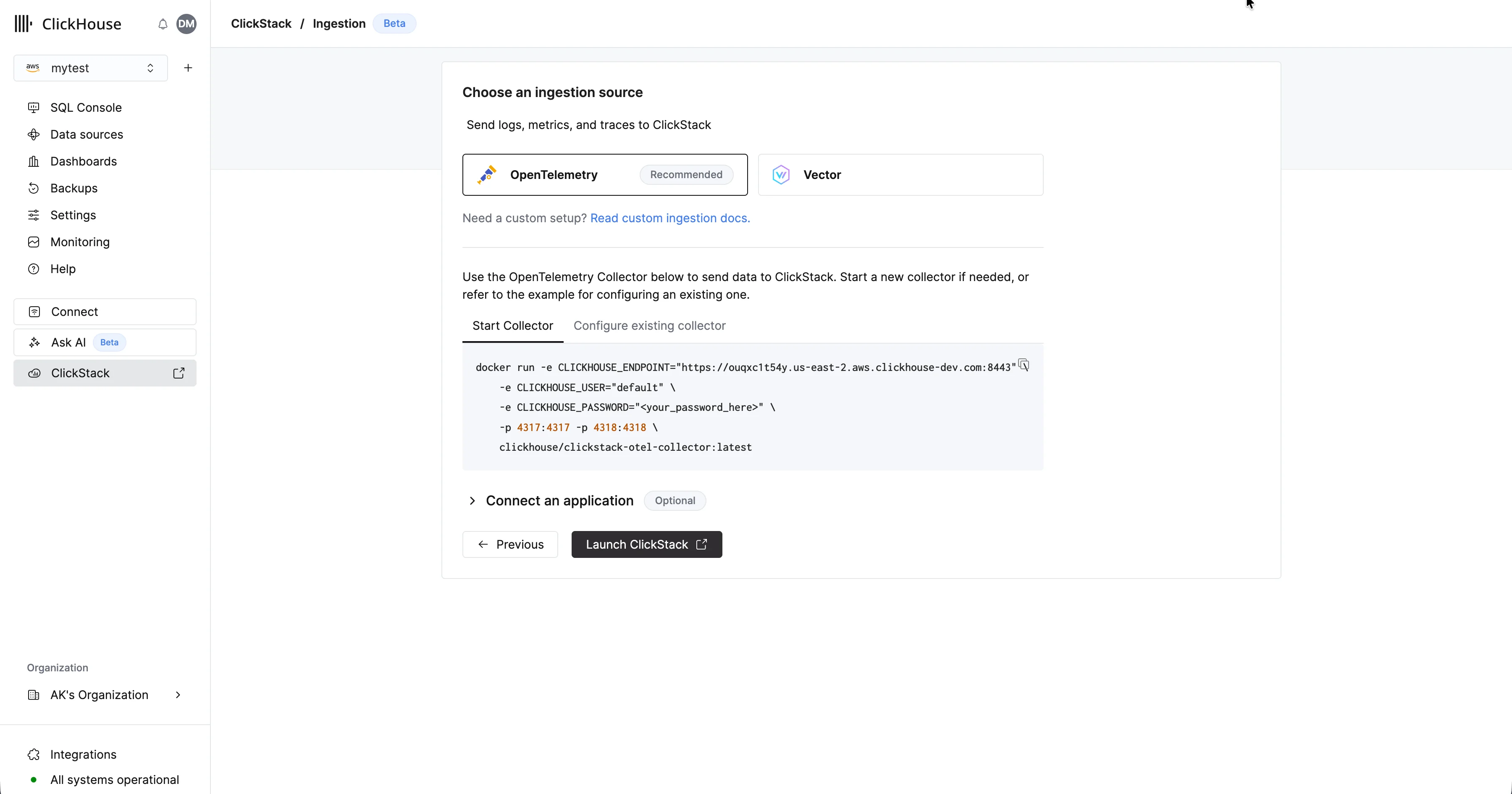
OpenTelemetry recomendadoSe recomienda encarecidamente usar OpenTelemetry como formato de ingestión.
Ofrece la experiencia más sencilla y optimizada, con esquemas listos para usar diseñados específicamente para funcionar de forma eficiente con ClickStack.
Para enviar datos de OpenTelemetry a Managed ClickStack, se recomienda usar un OpenTelemetry Collector. El collector actúa como un gateway que recibe datos de OpenTelemetry de sus aplicaciones (y de otros collectors) y los reenvía a ClickHouse Cloud.Si aún no tiene uno en ejecución, inicie un collector siguiendo los pasos a continuación. Si ya tiene collectors existentes, también se incluye un ejemplo de configuración.Iniciar un collector
A continuación se asume la ruta recomendada: usar la distribución de ClickStack de OpenTelemetry Collector, que incluye procesamiento adicional y está optimizada específicamente para ClickHouse Cloud. Si desea usar su propio OpenTelemetry Collector, consulte “Configurar collectors existentes.”Para empezar rápidamente, copie y ejecute el comando de Docker que se muestra.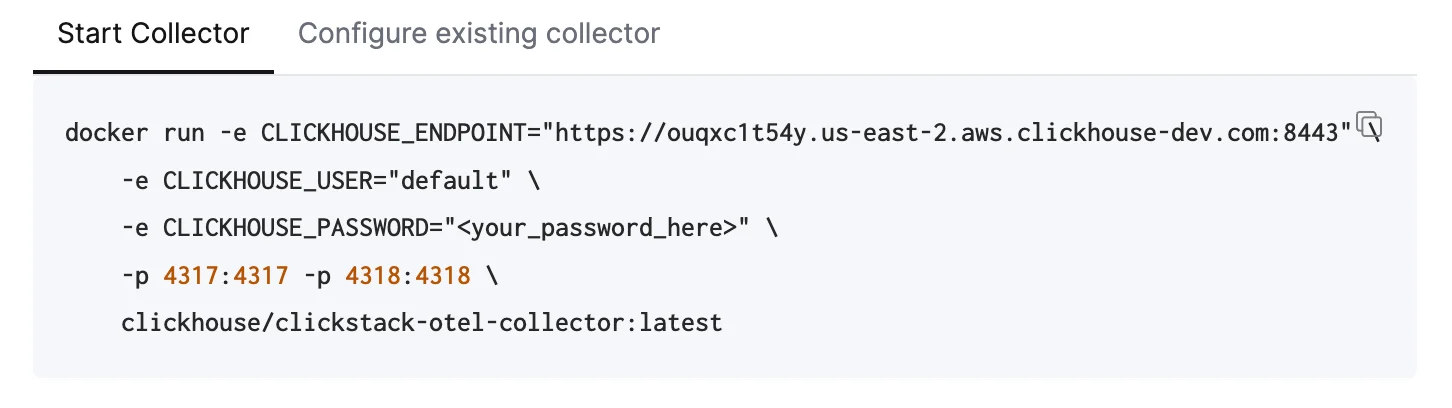 Este comando debería incluir sus credenciales de conexión ya rellenadas.
Este comando debería incluir sus credenciales de conexión ya rellenadas.Despliegue en producciónAunque este comando usa el usuario default para conectarse a Managed ClickStack, debería crear un usuario dedicado al pasar a producción y modificar su configuración. Configurar collectors existentes
También es posible configurar sus propios OpenTelemetry Collectors existentes o usar su propia distribución del collector.Para ello, se proporciona una configuración de ejemplo de OpenTelemetry Collector que usa el exportador de ClickHouse con la configuración adecuada y expone receivers de OTLP. Esta configuración coincide con las interfaces y el comportamiento esperados por la distribución de ClickStack.Para obtener más información sobre cómo configurar collectors de OpenTelemetry, consulte “Ingestión con OpenTelemetry.”Iniciar la ingestión (opcional)
Si tiene aplicaciones o infraestructura existentes para instrumentar con OpenTelemetry, vaya a las guías pertinentes enlazadas desde la UI.Para instrumentar sus aplicaciones y recopilar traces y logs, use los SDKs de lenguajes compatibles, que envían datos a su OpenTelemetry Collector, que actúa como gateway para la ingestión en Managed ClickStack.Los logs pueden recopilarse usando OpenTelemetry Collectors que se ejecutan en modo agent y reenvían datos al mismo collector. Para la monitorización de Kubernetes, siga la guía específica. Para otras integraciones, consulte nuestras guías de inicio rápido.Datos de demostración
Como alternativa, si no tiene datos existentes, pruebe uno de nuestros datasets de ejemplo.
- Dataset de ejemplo - Cargue un dataset de ejemplo de nuestra demo pública. Diagnostique un problema sencillo.
- Archivos locales y métricas - Cargue archivos locales y supervise el sistema en OSX o Linux usando un OTel collector local.
Vector es un pipeline de datos de observabilidad de alto rendimiento y neutral con respecto a los proveedores, especialmente popular para la ingestión de logs por su flexibilidad y bajo consumo de recursos.Al usar Vector con ClickStack, los usuarios son responsables de definir sus propios esquemas. Estos esquemas pueden seguir las convenciones de OpenTelemetry, pero también pueden ser completamente personalizados y representar estructuras de eventos definidas por el usuario.Timestamp obligatorioEl único requisito estricto para Managed ClickStack es que los datos incluyan una columna timestamp (o un campo de tiempo equivalente), que puede declararse al configurar la fuente de datos en la interfaz de usuario de ClickStack.
Crear una base de datos y una tabla
Vector requiere que la tabla y el esquema estén definidos antes de la ingestión de datos.Primero, crea una base de datos. Esto puede hacerse a través de la consola de ClickHouse Cloud.Por ejemplo, crea una base de datos para logs:CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
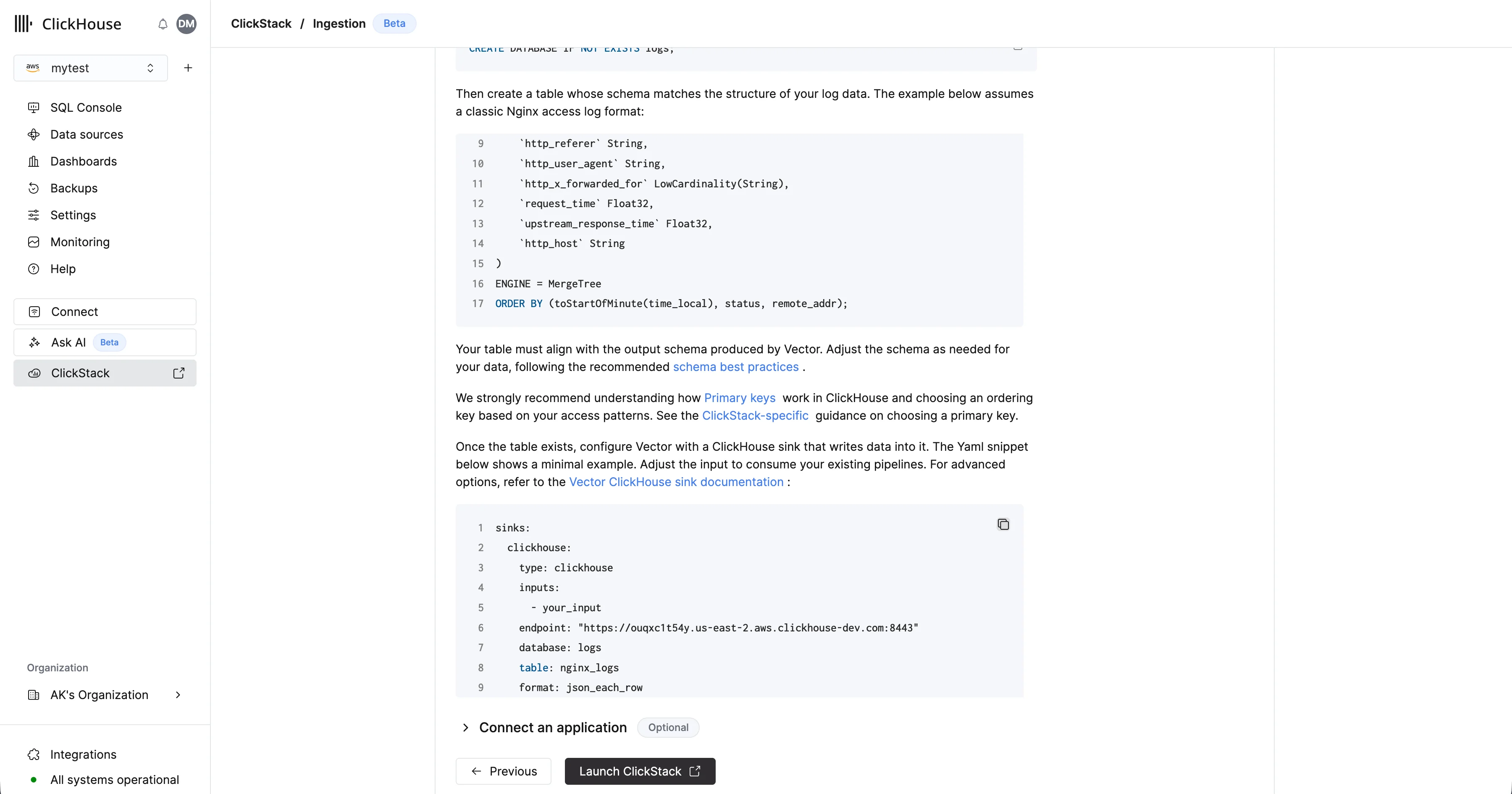 Para ver más ejemplos de ingesta de datos con Vector, consulta “Ingesta con Vector” o la documentación del sink de ClickHouse para Vector para opciones avanzadas.
Para ver más ejemplos de ingesta de datos con Vector, consulta “Ingesta con Vector” o la documentación del sink de ClickHouse para Vector para opciones avanzadas. Accede a la UI de ClickStack
Seleccione ‘Launch ClickStack’ para acceder a la interfaz de ClickStack (HyperDX). Se le autenticará automáticamente y se le redirigirá.Se crearán automáticamente orígenes de datos para todos los datos de OpenTelemetry.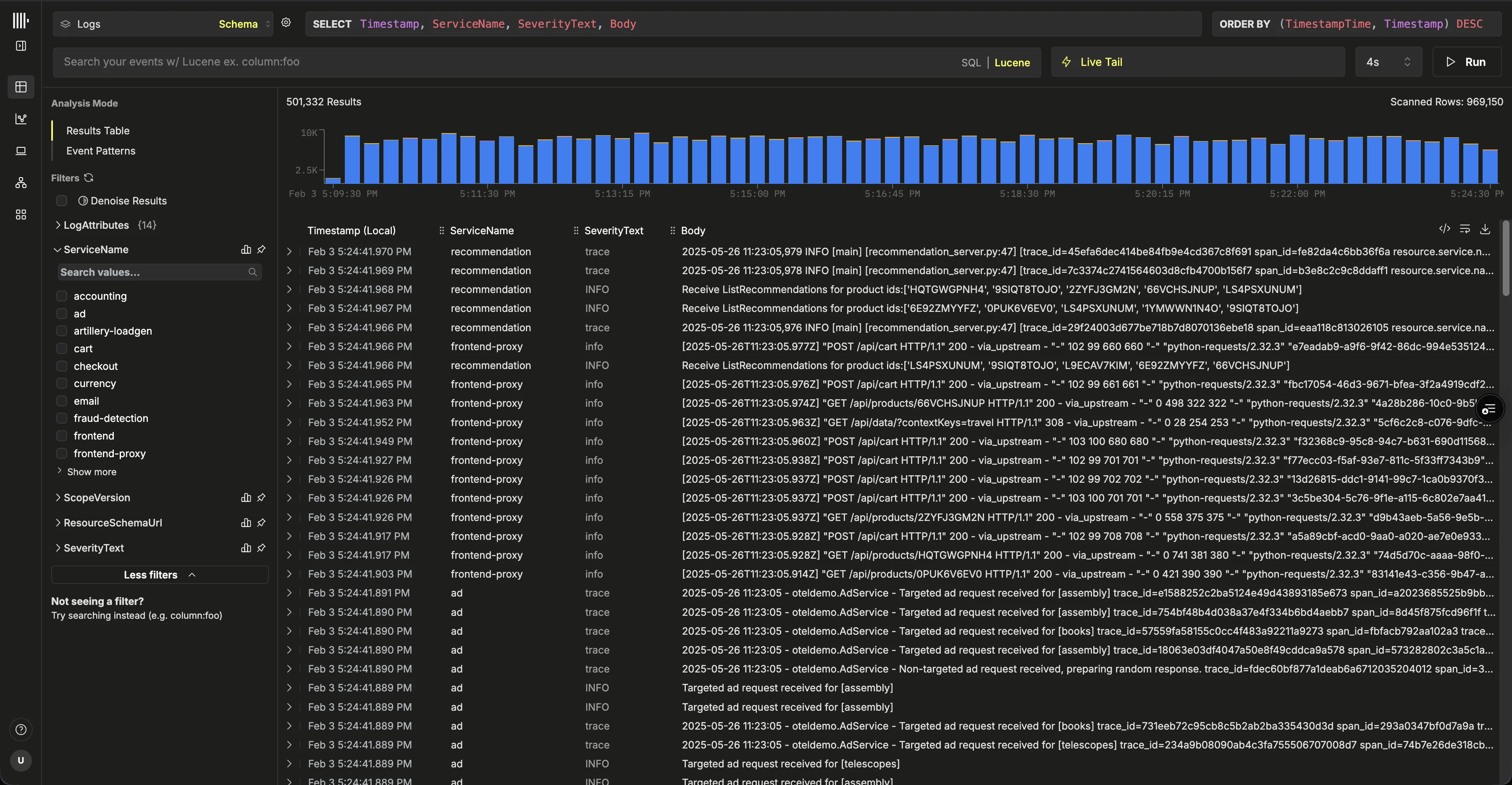
Si utiliza Vector, tendrá que crear sus propios orígenes de datos. Se le pedirá que cree uno al iniciar sesión por primera vez. A continuación, mostramos una configuración de ejemplo para un origen de datos de logs.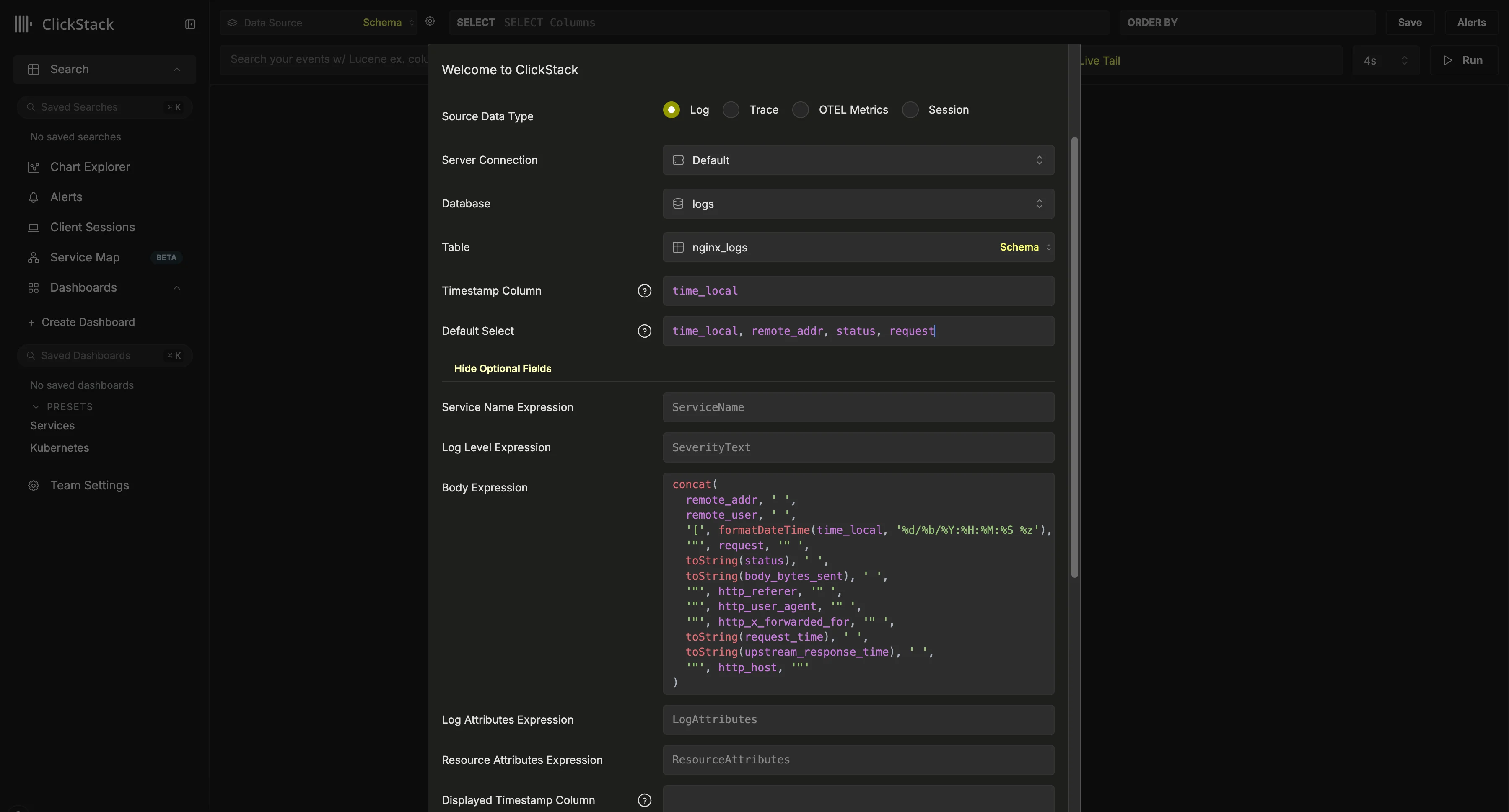 Esta configuración asume un esquema de estilo Nginx con una columna
Esta configuración asume un esquema de estilo Nginx con una columna time_local usada como timestamp. Siempre que sea posible, esta debería ser la columna de timestamp declarada en la clave primaria. Esta columna es obligatoria.También recomendamos actualizar Default SELECT para definir explícitamente qué columnas se devuelven en la vista de logs. Si hay campos adicionales disponibles, como el nombre del servicio, el nivel de log o una columna Body, también pueden configurarse. La columna de visualización del timestamp también puede sustituirse si difiere de la columna usada en la clave primaria de la tabla y configurada anteriormente.En el ejemplo anterior, no existe una columna Body en los datos. En su lugar, se define mediante una expresión SQL que reconstruye una línea de log de Nginx a partir de los campos disponibles.Para ver otras opciones, consulte la referencia de configuración.Una vez creado, debería ir a la vista de búsqueda, donde podrá empezar a explorar sus datos de inmediato. Selecciona un servicio
En la página principal de ClickHouse Cloud, selecciona el servicio en el que deseas habilitar Managed ClickStack.Estimación de recursosEsta guía asume que has aprovisionado recursos suficientes para manejar el volumen de datos de observabilidad que planeas ingestar y consultar con ClickStack. Para estimar los recursos necesarios, consulta la guía Estimación de recursos.Si tu servicio de ClickHouse ya aloja otras cargas de trabajo, como análisis de aplicaciones en tiempo real, te recomendamos crear un servicio hijo mediante la funcionalidad de warehouses de ClickHouse Cloud para aislar la carga de trabajo de observabilidad. Esto garantiza que tus aplicaciones actuales no se vean afectadas, mientras mantiene los conjuntos de datos accesibles desde ambos servicios. Ve a la UI de ClickStack
Selecciona ‘ClickStack’ en el menú de navegación de la izquierda. Se te redirigirá a la UI de ClickStack y se te autenticará automáticamente en función de tus permisos de ClickHouse Cloud.Si ya existen tablas de OpenTelemetry en tu servicio, se detectarán automáticamente y se crearán los orígenes de datos correspondientes.Detección automática de orígenes de datosLa detección automática se basa en el esquema estándar de tablas de OpenTelemetry proporcionado por la distribución ClickStack del OpenTelemetry Collector. Los orígenes de datos se crean para la base de datos con el conjunto de tablas más completo. Si es necesario, se pueden añadir tablas adicionales como orígenes de datos independientes. Configurar la ingestión
Si la detección automática falla o no hay tablas existentes, se te pedirá que configures la ingestión.Seleccione “Start Ingestion” y se le pedirá que elija una fuente de ingestión. Managed ClickStack admite OpenTelemetry y Vector como sus principales fuentes de ingestión. No obstante, los usuarios también tienen la opción de enviar datos directamente a ClickHouse con su propio schema mediante cualquiera de las integraciones compatibles con ClickHouse Cloud.Se recomienda OpenTelemetrySe recomienda encarecidamente el uso de OpenTelemetry como formato de ingestión.
Ofrece la experiencia más sencilla y optimizada, con esquemas listos para usar diseñados específicamente para funcionar de forma eficiente con ClickStack.
Para enviar datos de OpenTelemetry a Managed ClickStack, se recomienda usar un OpenTelemetry Collector. El collector actúa como gateway: recibe datos de OpenTelemetry de sus aplicaciones (y de otros collectors) y los reenvía a ClickHouse Cloud.Si todavía no tiene uno en ejecución, inicie un collector siguiendo los pasos a continuación. Si ya tiene collectors existentes, también se proporciona un ejemplo de configuración.Iniciar un collector
A continuación se asume la opción recomendada: usar la distribución de ClickStack de OpenTelemetry Collector, que incluye procesamiento adicional y está optimizada específicamente para ClickHouse Cloud. Si quiere usar su propio OpenTelemetry Collector, consulte “Configurar collectors existentes.”Para empezar rápidamente, copie y ejecute el comando de Docker que se muestra.Modifique este comando con las credenciales de su servicio, que anotó cuando creó el servicio.Despliegue en producciónAunque este comando usa el usuario default para conectarse a Managed ClickStack, debe crear un usuario dedicado cuando pase a producción y modificar su configuración. Configurar collectors existentes
También es posible configurar sus propios OpenTelemetry Collectors existentes o usar su propia distribución del collector.Para ello, se proporciona un ejemplo de configuración de OpenTelemetry Collector que usa el ClickHouse exporter con la configuración adecuada y expone receivers OTLP. Esta configuración coincide con las interfaces y el comportamiento esperados por la distribución de ClickStack.A continuación se muestra un ejemplo de esta configuración (las variables de entorno se completarán automáticamente si se copian desde la UI):receivers:
otlp/hyperdx:
protocols:
grpc:
include_metadata: true
endpoint: "0.0.0.0:4317"
http:
cors:
allowed_origins: ["*"]
allowed_headers: ["*"]
include_metadata: true
endpoint: "0.0.0.0:4318"
processors:
batch:
memory_limiter:
# 80% de la memoria máxima hasta 2G, ajustar para entornos con poca memoria
limit_mib: 1500
# 25% del límite hasta 2G, ajustar para entornos con poca memoria
spike_limit_mib: 512
check_interval: 5s
connectors:
routing/logs:
default_pipelines: [logs/out-default]
error_mode: ignore
table:
- context: log
statement: route() where IsMatch(attributes["rr-web.event"], ".*")
pipelines: [logs/out-rrweb]
exporters:
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
clickhouse/rrweb:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
logs_table_name: hyperdx_sessions
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
clickhouse:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
traces:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
metrics:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/in:
receivers: [otlp/hyperdx]
exporters: [routing/logs]
logs/out-default:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/out-rrweb:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse/rrweb]
Iniciar la ingestión (opcional)
Si tiene aplicaciones o infraestructura existentes que quiera instrumentar con OpenTelemetry, vaya a las guías correspondientes enlazadas desde “Conectar una aplicación”.Para instrumentar sus aplicaciones y recopilar traces y logs, use los SDK de lenguaje compatibles, que envían datos a su OpenTelemetry Collector, que actúa como gateway para la ingestión en Managed ClickStack.Los logs pueden recopilarse con OpenTelemetry Collectors que se ejecutan en modo agent y reenvían datos al mismo collector. Para el monitoreo de Kubernetes, siga la guía específica. Para otras integraciones, consulte nuestras guías de inicio rápido. Vector es una canalización de datos de observabilidad de alto rendimiento e independiente del proveedor, especialmente popular para la ingestión de logs por su flexibilidad y su bajo consumo de recursos.Al usar Vector con ClickStack, los usuarios son responsables de definir sus propios esquemas. Estos esquemas pueden seguir las convenciones de OpenTelemetry, pero también pueden ser totalmente personalizados y representar estructuras de eventos definidas por el usuario.Se requiere un timestampEl único requisito estricto para Managed ClickStack es que los datos incluyan una columna de timestamp (o un campo de tiempo equivalente), que puede declararse al configurar la fuente de datos en la UI de ClickStack.
Crear una base de datos y una tabla
Vector requiere que se definan una tabla y un esquema antes de la ingestión de datos.Primero, crea una base de datos. Esto puede hacerse desde la consola de ClickHouse Cloud.Por ejemplo, crea una base de datos para logs:CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
Ve a la UI de ClickStack
Una vez que hayas terminado de configurar la ingestión y hayas comenzado a enviar datos, selecciona “Siguiente”.Si has ingerido datos de OpenTelemetry con esta guía, los orígenes de datos se crean automáticamente y no se requiere ninguna configuración adicional. Puedes empezar a explorar ClickStack de inmediato. Se te dirigirá a la vista de búsqueda con un origen seleccionado automáticamente para que puedas comenzar a hacer consultas enseguida.Eso es todo: ya está todo listo 🎉.
Si has ingerido datos a través de Vector o de otro origen, se te pedirá que configures el origen de datos.La configuración anterior asume un esquema de estilo Nginx con una columna time_local usada como timestamp. Siempre que sea posible, esta debe ser la columna de timestamp declarada en la clave primaria. Esta columna es obligatoria.También recomendamos actualizar Default SELECT para definir explícitamente qué columnas se devuelven en la vista de logs. Si hay campos adicionales disponibles, como el nombre del servicio, el nivel de log o una columna body, estos también pueden configurarse. La columna que se muestra como timestamp también puede sobrescribirse si es distinta de la columna usada en la clave primaria de la tabla y configurada anteriormente.En el ejemplo anterior, no existe una columna Body en los datos. En su lugar, se define mediante una expresión SQL que reconstruye una línea de log de Nginx a partir de los campos disponibles.Para ver otras opciones posibles, consulta la referencia de configuración.Una vez configurado el origen, haz clic en “Guardar” y empieza a explorar tus datos.
- Vaya a su servicio en la consola de ClickHouse Cloud
- Vaya a Settings → SQL Console Access
- Establezca el nivel de acceso adecuado para cada usuario:
- Service Admin → Full Access - Necesario para habilitar alertas
- Service Read Only → Read Only - Puede ver datos de observabilidad y crear dashboards
- No access - No puede acceder a HyperDX
Las alertas requieren acceso de administradorPara habilitar las alertas, al menos un usuario con permisos de Service Admin (asignado a Full Access en el menú desplegable SQL Console Access) debe iniciar sesión en HyperDX al menos una vez. Esto aprovisiona un usuario dedicado en la base de datos que ejecuta las consultas de alertas.
Uso de ClickStack con capacidad de cómputo de solo lectura
Cómo ClickStack selecciona la capacidad de cómputo
- Si abres ClickStack desde un servicio de solo lectura, todas las consultas emitidas por la UI de ClickStack se ejecutarán en esa capacidad de cómputo de solo lectura.
- Si abres ClickStack desde un servicio de lectura y escritura, ClickStack usará esa capacidad de cómputo en su lugar.
No se requiere ninguna configuración adicional dentro de ClickStack para garantizar el comportamiento de solo lectura.
Configuración recomendada
- Cree o identifique un servicio de ClickHouse Cloud en el warehouse configurado como de solo lectura.
- En la consola de ClickHouse Cloud, seleccione el servicio de solo lectura.
- Inicie ClickStack desde el menú de navegación de la izquierda.
Una vez iniciado, la UI de ClickStack quedará vinculada automáticamente a este servicio de solo lectura.
Añadir más fuentes de datos
Uso de esquemas de OpenTelemetry
Table con el valor otel_logs para crear una fuente de logs. El resto de la configuración debería detectarse automáticamente, lo que le permitirá hacer clic en Save New Source.
Para crear fuentes para traces y metrics de OTel, puede seleccionar Crear nueva fuente en el menú superior.
Desde aquí, seleccione el tipo de fuente requerido y, a continuación, la tabla adecuada; por ejemplo, para traces, seleccione la tabla otel_traces. Toda la configuración debería detectarse automáticamente.
Fuentes correlacionadasTenga en cuenta que distintas fuentes de datos en ClickStack, como logs y traces, pueden correlacionarse entre sí. Para habilitar esto, se requiere configuración adicional en cada fuente. Por ejemplo, en la fuente de logs puede especificar la fuente de traces correspondiente, y viceversa en la fuente de traces. Consulte “Fuentes correlacionadas” para obtener más información. Uso de esquemas personalizados
Elección del esquema: Map vs JSON
Map(LowCardinality(String), String) de forma predeterminada. Este es el esquema recomendado para las cargas de trabajo de observabilidad. En combinación con la serialización de mapas por buckets y los índices de texto sobre las claves y los valores del mapa, ofrece lookups selectivos sin la sobrecarga de ingesta por clave de las subcolumnas JSON dinámicas.
También hay disponible, en fase beta, un esquema de tipo JSON para evaluarlo en cargas de trabajo con un conjunto pequeño y estable de claves de atributos. No se recomienda como opción predeterminada. Consulta Map vs tipo JSON para ver la comparación completa y las variables de entorno necesarias para habilitar la compatibilidad con JSON.