Это руководство предназначено для существующих пользователей ClickHouse Cloud. Если вы только начинаете работать с ClickHouse Cloud, рекомендуем руководство Начало работы по Управляемому ClickStack.
В этом варианте развертывания и ClickHouse, и интерфейс ClickStack (HyperDX) размещаются в ClickHouse Cloud, что сводит к минимуму количество компонентов, которые пользователю нужно поддерживать самостоятельно.
Помимо сокращения затрат на управление инфраструктурой, этот вариант развертывания обеспечивает интеграцию аутентификации с ClickHouse Cloud SSO/SAML. В отличие от самоуправляемых развертываний, здесь также не нужно разворачивать экземпляр MongoDB для хранения состояния приложения — например, панелей мониторинга, сохранённых поисков, пользовательских настроек и оповещений. Пользователи также получают:
- Автоматическое масштабирование вычислительных ресурсов независимо от хранилища
- Недорогое и практически неограниченное хранение на базе объектного хранилища
- Возможность независимо изолировать рабочие нагрузки чтения и записи с помощью хранилищ.
- Интегрированную аутентификацию
- Автоматизированные резервные копии
- Функции безопасности и соответствия требованиям
- Беспроблемные обновления
В этом режиме ингестия данных полностью остаётся в зоне ответственности пользователя. Вы можете отправлять данные в Управляемый ClickStack с помощью собственного OpenTelemetry Collector, прямой ингестии из клиентских библиотек, встроенных в ClickHouse движков таблиц (например, Kafka или S3), ETL-конвейеров или ClickPipes — управляемого сервиса ингестии ClickHouse Cloud. Такой подход обеспечивает самый простой и производительный способ работы с ClickStack.
Эта схема развертывания идеально подходит в следующих случаях:
- У вас уже есть данные обсервабилити в ClickHouse Cloud, и вы хотите визуализировать их с помощью ClickStack.
- Вы управляете крупномасштабным развертыванием обсервабилити и вам нужны выделенные производительность и масштабируемость ClickStack, работающего на ClickHouse Cloud.
- Вы уже используете ClickHouse Cloud для аналитики и хотите инструментировать приложение с помощью библиотек инструментации ClickStack, отправляя данные в тот же кластер. В этом случае мы рекомендуем использовать хранилища, чтобы изолировать вычислительные ресурсы для рабочих нагрузок обсервабилити.
В этом руководстве предполагается, что вы уже создали сервис ClickHouse Cloud. Если вы еще не создали сервис, воспользуйтесь руководством Начало работы по Управляемому ClickStack. В результате вы получите сервис в том же состоянии, что и в этом руководстве, то есть готовый к приему данных обсервабилити с включенным ClickStack.
Создайте новый сервис
На главной странице ClickHouse Cloud выберите New service, чтобы создать новый сервис.Укажите провайдера, регион и ресурс
Scale vs EnterpriseМы рекомендуем этот уровень Scale для большинства рабочих нагрузок ClickStack. Выберите уровень Enterprise, если вам нужны расширенные возможности безопасности, такие как SAML, CMEK или соответствие требованиям HIPAA. Он также предлагает настраиваемые аппаратные профили для очень крупных развертываний ClickStack. В таких случаях рекомендуем обратиться в поддержку.  При выборе объёма CPU и памяти ориентируйтесь на ожидаемую пропускную способность ингестии ClickStack. В таблице ниже приведены рекомендации по подбору этих ресурсов.
При выборе объёма CPU и памяти ориентируйтесь на ожидаемую пропускную способность ингестии ClickStack. В таблице ниже приведены рекомендации по подбору этих ресурсов.| Месячный объём ингестии | Рекомендуемые вычислительные ресурсы |
|---|
| < 10 TB / month | 2 vCPU × 3 реплики |
| 10–50 TB / month | 4 vCPU × 3 реплики |
| 50–100 TB / month | 8 vCPU × 3 реплики |
| 100–500 TB / month | 30 vCPU × 3 реплики |
| 1 PB+ / month | 59 vCPU × 3 реплики |
- Под объёмом данных понимается месячный объём ингестии в несжатом виде; это относится как к журналам, так и к трейсам.
- Шаблоны запросов типичны для сценариев обсервабилити, при этом большинство запросов нацелено на недавние данные, обычно за последние 24 часа.
- Ингестия происходит относительно равномерно в течение месяца. Если вы ожидаете всплески трафика или пики, следует предусмотреть дополнительный запас ресурсов.
- Хранение организовано отдельно через Объектное хранилище ClickHouse Cloud и не является ограничивающим фактором для срока хранения. Мы предполагаем, что к данным, хранящимся длительное время, обращаются нечасто.
Для шаблонов доступа, которые регулярно охватывают более длинные временные диапазоны, выполняют тяжёлые агрегации или рассчитаны на большое число одновременных пользователей, может потребоваться больше вычислительных ресурсов.Хотя две реплики могут удовлетворить требованиям к CPU и памяти для заданной пропускной способности ингестии, мы рекомендуем по возможности использовать три реплики, чтобы обеспечить ту же суммарную ёмкость и повысить отказоустойчивость сервиса.Эти значения — лишь ориентировочные и должны использоваться как отправная точка. Фактические требования зависят от сложности запросов, параллелизма, политик хранения и вариативности пропускной способности ингестии. Всегда отслеживайте использование ресурсов и при необходимости масштабируйте их.
Настройте ингестию
После подготовки сервиса убедитесь, что он выбран, и выберите “ClickStack” в левом меню. Выберите “Начать ингестию”, и вам будет предложено выбрать источник ингестии. Управляемый ClickStack поддерживает OpenTelemetry и Vector в качестве основных источников ингестии. Однако пользователи также могут отправлять данные напрямую в ClickHouse в собственной схеме, используя любые из интеграций, поддерживаемых ClickHouse Cloud.
Выберите “Начать ингестию”, и вам будет предложено выбрать источник ингестии. Управляемый ClickStack поддерживает OpenTelemetry и Vector в качестве основных источников ингестии. Однако пользователи также могут отправлять данные напрямую в ClickHouse в собственной схеме, используя любые из интеграций, поддерживаемых ClickHouse Cloud.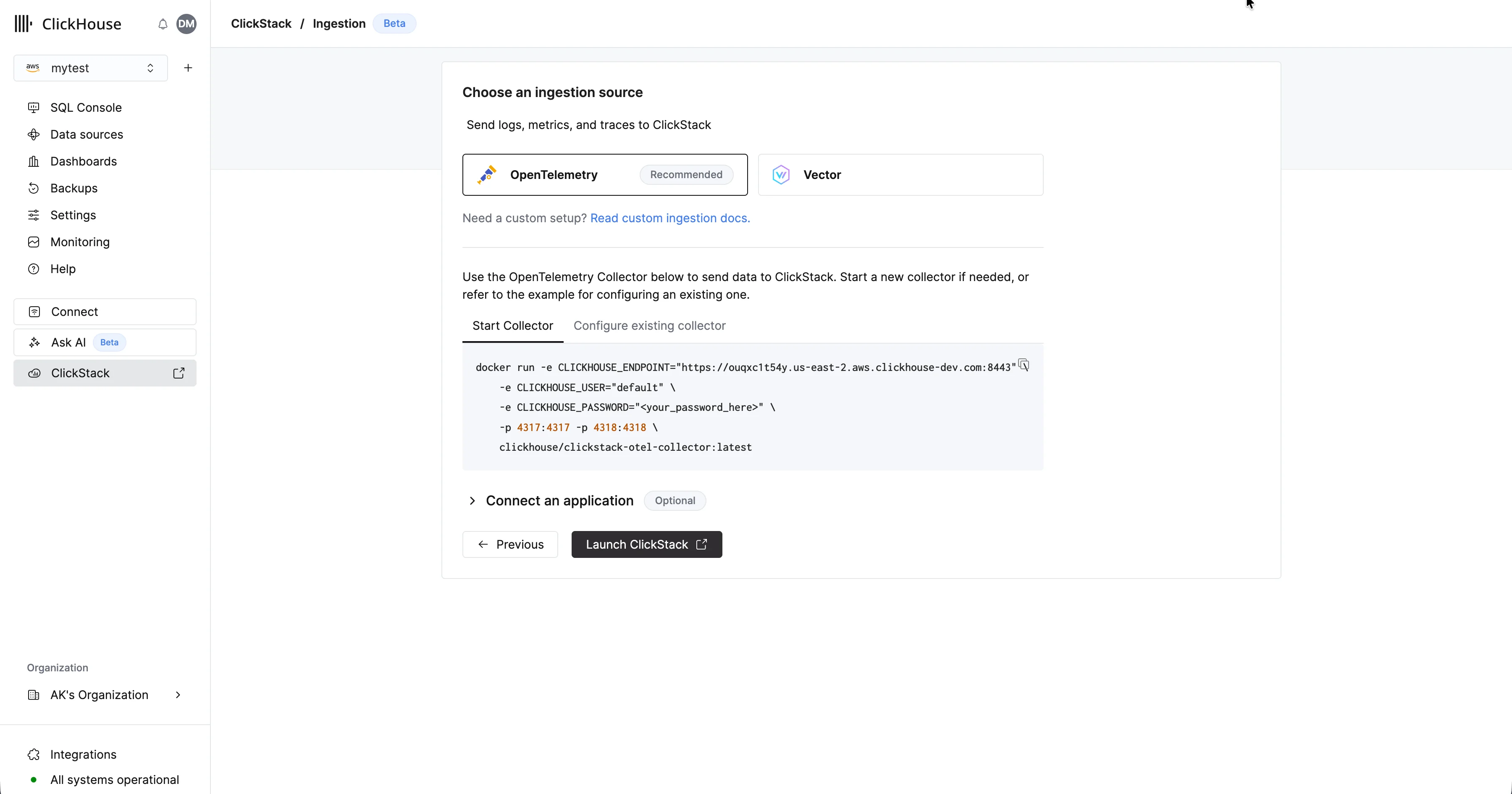
Рекомендуем OpenTelemetryНастоятельно рекомендуется использовать OpenTelemetry в качестве формата для ингестии.
Он обеспечивает максимально простой и оптимизированный процесс благодаря готовым схемам, специально разработанным для эффективной работы с ClickStack.
Чтобы отправлять данные OpenTelemetry в Управляемый ClickStack, рекомендуется использовать OpenTelemetry Collector. Коллектор выступает в роли шлюза: он получает данные OpenTelemetry от ваших приложений (и других коллекторов) и пересылает их в ClickHouse Cloud.Если у вас коллектор еще не запущен, выполните приведенные ниже шаги. Если у вас уже есть существующие коллекторы, ниже также приведен пример конфигурации.Запуск коллектора
Ниже рассматривается рекомендуемый вариант — использование дистрибутива ClickStack для OpenTelemetry Collector, который включает дополнительную обработку и специально оптимизирован для ClickHouse Cloud. Если вы хотите использовать собственный OpenTelemetry Collector, см. “Настройка существующих коллекторов.”Чтобы быстро начать, скопируйте и выполните показанную команду Docker.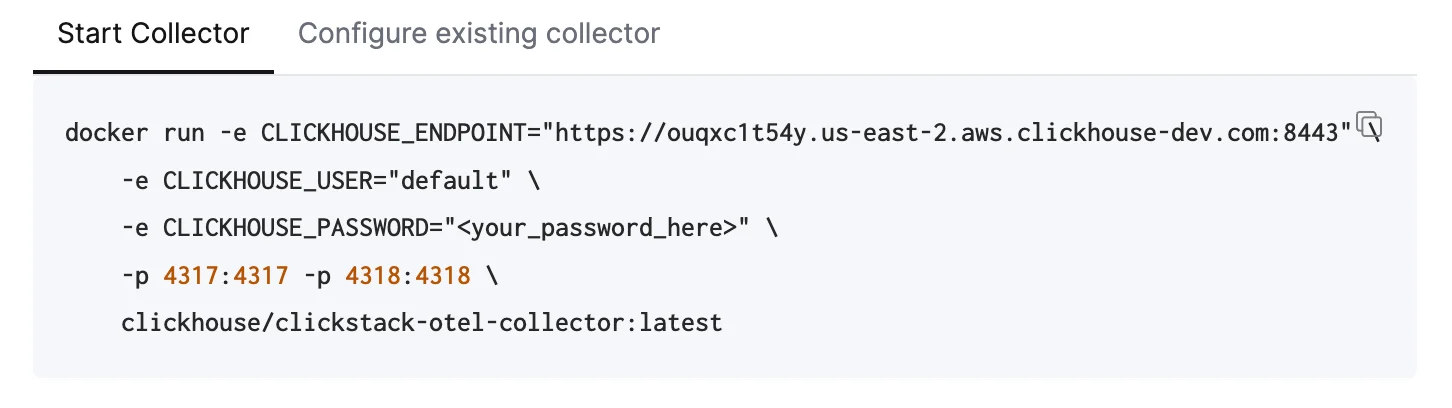 Эта команда должна уже содержать ваши учетные данные для подключения.
Эта команда должна уже содержать ваши учетные данные для подключения.Развертывание в productionХотя в этой команде для подключения к Управляемому ClickStack используется пользователь default, при переходе в production и изменении конфигурации следует создать отдельного пользователя. Настройка существующих коллекторов
Вы также можете настроить собственные OpenTelemetry Collectors или использовать собственный дистрибутив коллектора.Для этого вам предоставляется пример конфигурации OpenTelemetry Collector, в которой используется ClickHouse exporter с подходящими настройками и открыты приёмники OTLP. Эта конфигурация соответствует интерфейсам и поведению, ожидаемым дистрибутивом ClickStack.Дополнительные сведения о настройке коллекторов OpenTelemetry см. в разделе “Ингестия с OpenTelemetry.”Запуск ингестии (необязательно)
Если у вас есть существующие приложения или инфраструктура, которые нужно инструментировать с помощью OpenTelemetry, перейдите к соответствующим руководствам по ссылкам в интерфейсе.Чтобы инструментировать приложения для сбора трассировок и журналов, используйте поддерживаемые SDK для языков, которые отправляют данные в ваш OpenTelemetry Collector, выступающий в роли шлюза для ингестии в Управляемый ClickStack.Журналы можно собирать с помощью коллекторов OpenTelemetry, работающих в режиме агента и пересылающих данные в тот же коллектор. Для мониторинга Kubernetes следуйте отдельному руководству. Для других интеграций см. наши краткие руководства.Демонстрационные данные
Если у вас пока нет собственных данных, попробуйте один из наших примеров наборов данных.
- Пример набора данных - Загрузите пример набора данных из нашей публичной демоверсии. Диагностируйте простую проблему.
- Локальные файлы и метрики - Загрузите локальные файлы и отслеживайте систему в OSX или Linux с помощью локального OTel collector.
Vector — это высокопроизводительный, не зависящий от поставщика конвейер данных для обсервабилити, особенно популярный для приёма журналов благодаря гибкости и низкому потреблению ресурсов.При использовании Vector с ClickStack пользователи сами определяют схемы. Эти схемы могут соответствовать соглашениям OpenTelemetry, но также могут быть полностью произвольными и описывать пользовательские структуры событий.Требуется timestampЕдинственное строгое требование для Управляемого ClickStack — данные должны содержать столбец timestamp (или эквивалентное поле времени), который можно указать при настройке источника данных в интерфейсе ClickStack.
Создайте базу данных и таблицу
Для Vector необходимо, чтобы таблица и схема были определены до начала ингестии данных.Сначала создайте базу данных. Это можно сделать через консоль ClickHouse Cloud.Например, создайте базу данных для журналов:CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
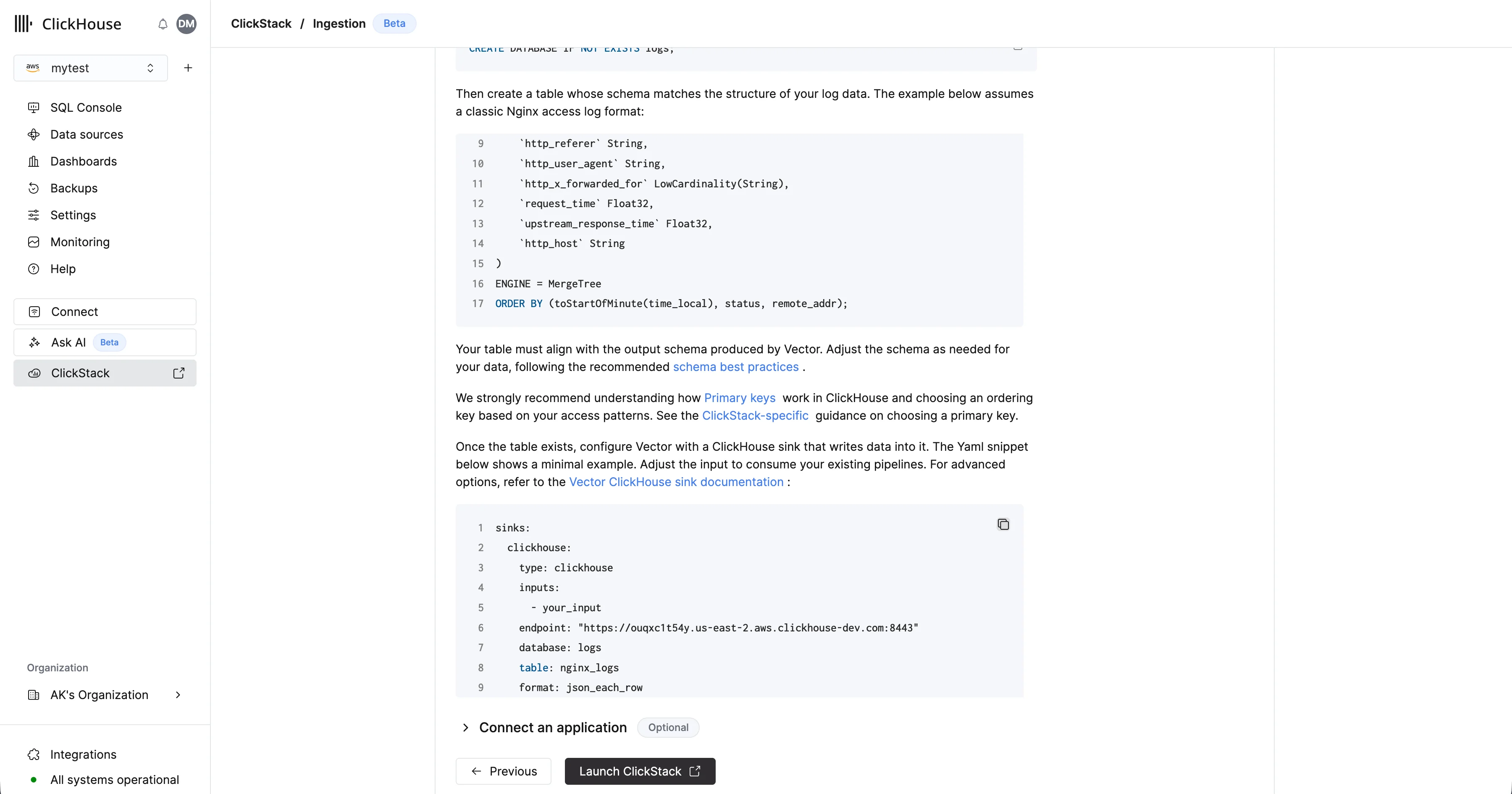 Больше примеров ингестии данных с Vector см. в разделе “Ингестия с Vector” или в документации по sink ClickHouse в Vector для расширенных настроек.
Больше примеров ингестии данных с Vector см. в разделе “Ингестия с Vector” или в документации по sink ClickHouse в Vector для расширенных настроек. Перейдите в интерфейс ClickStack
Выберите ‘Launch ClickStack’, чтобы открыть интерфейс ClickStack (HyperDX). Вход выполнится автоматически, и вы будете перенаправлены.Источники данных будут заранее созданы для любых данных OpenTelemetry.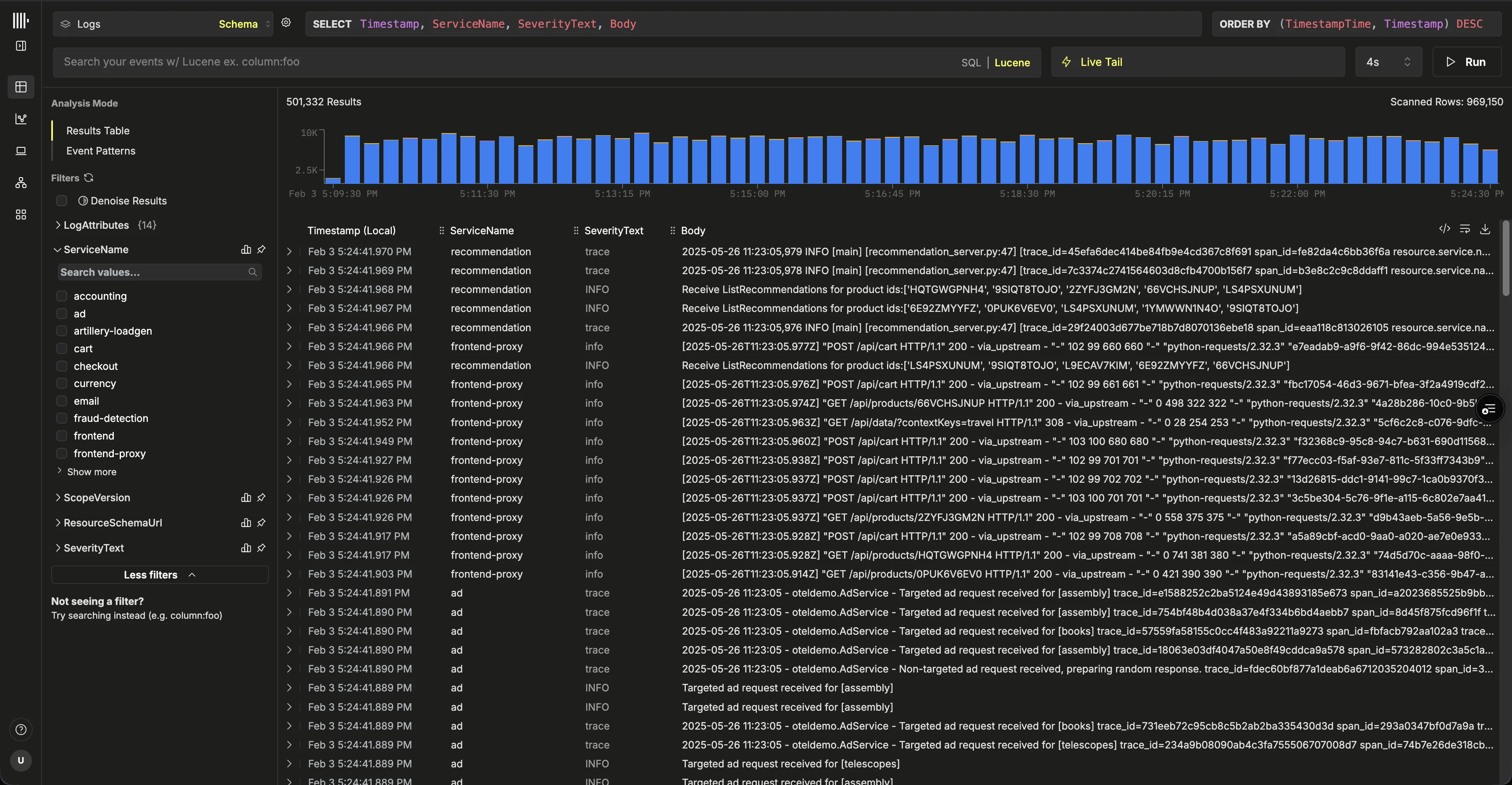
Если вы используете Vector, вам потребуется создать собственные источники данных. При первом входе вам будет предложено создать источник данных. Ниже приведён пример конфигурации для источника данных журналов.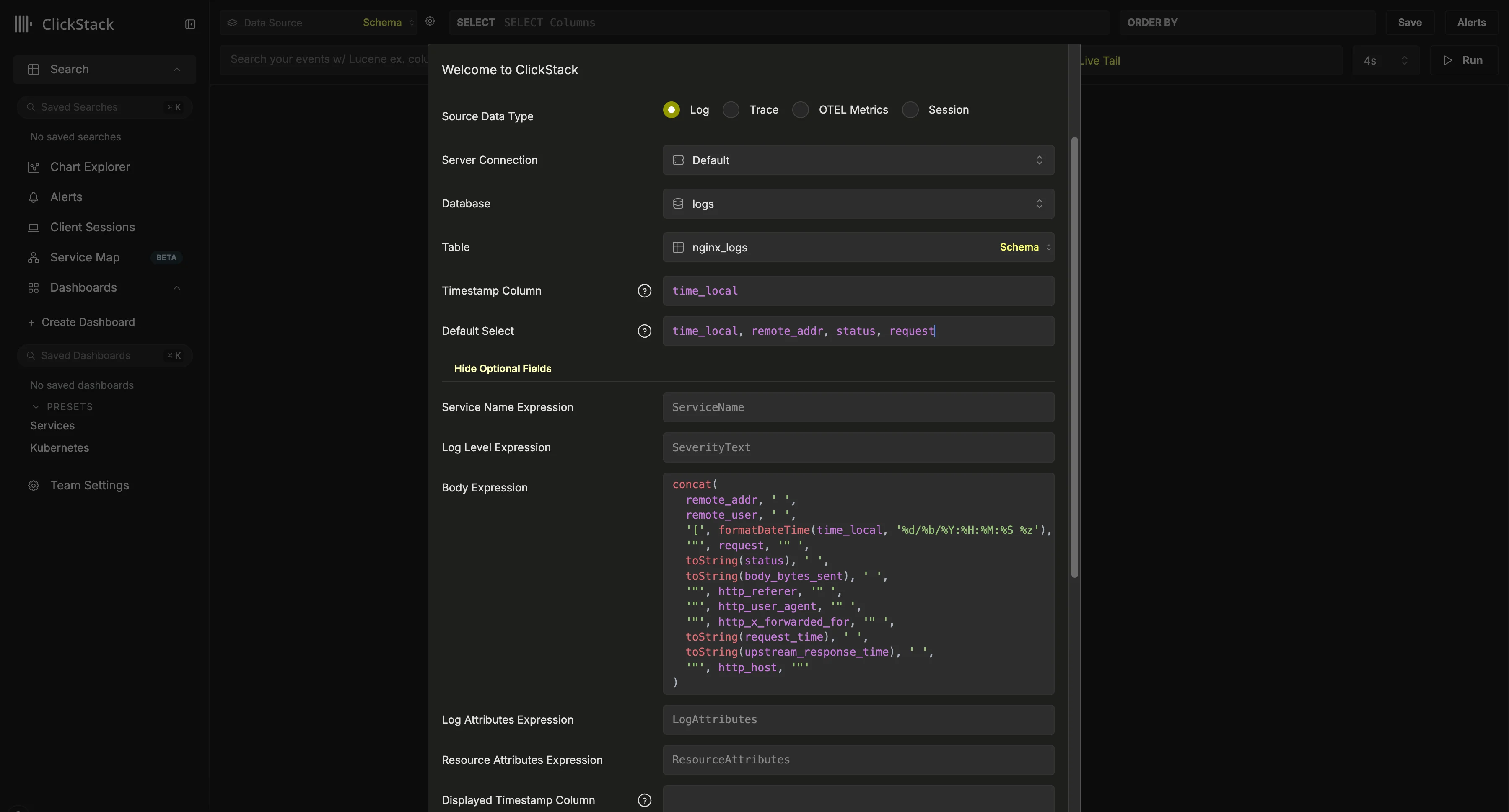 Эта конфигурация предполагает схему в стиле Nginx, где столбец
Эта конфигурация предполагает схему в стиле Nginx, где столбец time_local используется как временная метка. По возможности это должен быть столбец временной метки, объявленный в первичном ключе. Этот столбец обязателен.Мы также рекомендуем обновить Default SELECT, чтобы явно указать, какие столбцы возвращаются в представлении журналов. Если доступны дополнительные поля, такие как имя сервиса, уровень журнала или столбец с телом сообщения, их тоже можно настроить. Столбец, отображаемый как временная метка, также можно переопределить, если он отличается от столбца, используемого в первичном ключе таблицы и настроенного выше.В примере выше столбец Body отсутствует в данных. Вместо этого он задаётся с помощью SQL-выражения, которое воссоздаёт строку журнала Nginx из доступных полей.О других возможных параметрах см. в справочнике по конфигурации.После создания вы должны попасть в представление поиска, где сможете сразу начать изучать свои данные. Выберите сервис
На главной странице ClickHouse Cloud выберите сервис, для которого нужно включить Управляемый ClickStack.Оценка ресурсовВ этом руководстве предполагается, что вы уже выделили достаточно ресурсов для обработки объёма данных обсервабилити, приём которых планируете настроить, и выполнения запросов к ним с помощью ClickStack. Чтобы оценить необходимые ресурсы, обратитесь к руководству Estimating Resources.Если ваш сервис ClickHouse уже используется для существующих рабочих нагрузок, например аналитики приложений в реальном времени, мы рекомендуем создать дочерний сервис с помощью функции хранилищ ClickHouse Cloud, чтобы изолировать рабочую нагрузку обсервабилити. Это позволит не влиять на работу существующих приложений и при этом сохранить доступ к наборам данных из обоих сервисов. Перейдите в интерфейс ClickStack
Выберите ‘ClickStack’ в левом навигационном меню. Вы будете перенаправлены в интерфейс ClickStack и автоматически авторизованы в соответствии с вашими правами доступа ClickHouse Cloud.Если в вашем сервисе уже есть таблицы OpenTelemetry, они будут обнаружены автоматически, и для них будут созданы соответствующие источники данных.Автообнаружение источников данныхАвтообнаружение использует стандартную схему таблиц OpenTelemetry, предоставляемую дистрибутивом ClickStack для OpenTelemetry Collector. Источники создаются для базы данных с наиболее полным набором таблиц. При необходимости дополнительные таблицы можно добавить как отдельные источники данных. Настройка ингестии
Если автоматическое обнаружение завершится неудачей или у вас нет существующих таблиц, система предложит вам настроить ингестию.Выберите “Start Ingestion” — вам будет предложено выбрать источник ингестии. Управляемый ClickStack поддерживает OpenTelemetry и Vector в качестве основных источников ингестии. При этом пользователи также могут отправлять данные напрямую в ClickHouse в собственной схеме, используя любую из интеграций, поддерживаемых ClickHouse Cloud.Рекомендуется OpenTelemetryНастоятельно рекомендуется использовать OpenTelemetry в качестве формата ингестии.
Он обеспечивает максимально простой и оптимизированный вариант благодаря готовым схемам, специально разработанным для эффективной работы с ClickStack.
Чтобы отправлять данные OpenTelemetry в Управляемый ClickStack, рекомендуется использовать OpenTelemetry Collector. Он выступает в роли шлюза: принимает данные OpenTelemetry от ваших приложений (и других коллекторов) и пересылает их в ClickHouse Cloud.Если у вас ещё нет запущенного коллектора, запустите его, выполнив шаги ниже. Если у вас уже есть коллекторы, ниже также приведён пример конфигурации.Запуск коллектора
Ниже рассматривается рекомендуемый вариант — использование дистрибутива ClickStack для OpenTelemetry Collector, который включает дополнительную обработку и оптимизирован специально для ClickHouse Cloud. Если вы хотите использовать собственный OpenTelemetry Collector, см. “Настройка существующих коллекторов”Чтобы быстро начать, скопируйте и выполните показанную Docker-команду.Измените эту команду, подставив учётные данные вашего сервиса, сохранённые при его создании.Развёртывание в продакшнХотя в этой команде для подключения к Управляемому ClickStack используется пользователь default, при переходе в продакшн и изменении конфигурации следует создать отдельного пользователя. Настройка существующих коллекторов
Вы также можете настроить собственные OpenTelemetry Collectors или использовать свой дистрибутив коллектора.Для этого также предоставляется пример конфигурации OpenTelemetry Collector, использующей ClickHouse exporter с подходящими настройками и открывающей OTLP receivers. Эта конфигурация соответствует интерфейсам и поведению, ожидаемым дистрибутивом ClickStack.Ниже показан пример этой конфигурации (при копировании из интерфейса переменные среды будут заполнены автоматически):receivers:
otlp/hyperdx:
protocols:
grpc:
include_metadata: true
endpoint: "0.0.0.0:4317"
http:
cors:
allowed_origins: ["*"]
allowed_headers: ["*"]
include_metadata: true
endpoint: "0.0.0.0:4318"
processors:
batch:
memory_limiter:
# 80% максимальной памяти до 2G, скорректируйте для сред с ограниченным объёмом памяти
limit_mib: 1500
# 25% от лимита до 2G, скорректируйте для сред с ограниченным объёмом памяти
spike_limit_mib: 512
check_interval: 5s
connectors:
routing/logs:
default_pipelines: [logs/out-default]
error_mode: ignore
table:
- context: log
statement: route() where IsMatch(attributes["rr-web.event"], ".*")
pipelines: [logs/out-rrweb]
exporters:
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
clickhouse/rrweb:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
logs_table_name: hyperdx_sessions
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
clickhouse:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
traces:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
metrics:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/in:
receivers: [otlp/hyperdx]
exporters: [routing/logs]
logs/out-default:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/out-rrweb:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse/rrweb]
Начало ингестии (необязательно)
Если у вас уже есть приложения или инфраструктура, которые нужно инструментировать с помощью OpenTelemetry, перейдите к соответствующим руководствам по ссылкам из раздела “Подключить приложение”.Чтобы инструментировать приложения для сбора трассировок и журналов, используйте SDK для поддерживаемых языков, которые отправляют данные в ваш OpenTelemetry Collector, выступающий в роли шлюза для ингестии в Управляемый ClickStack.Журналы можно собирать с помощью OpenTelemetry Collectors, работающих в режиме agent и пересылающих данные в тот же коллектор. Для мониторинга Kubernetes следуйте специальному руководству. Для других интеграций см. наши руководства по быстрому старту. Vector — это высокопроизводительный, не зависящий от поставщика конвейер данных для обсервабилити, особенно популярный для ингестии логов благодаря своей гибкости и низкому потреблению ресурсов.При использовании Vector с ClickStack пользователи сами определяют схемы. Эти схемы могут соответствовать соглашениям OpenTelemetry, но также могут быть полностью пользовательскими и описывать заданные пользователем структуры событий.Требуется временная меткаЕдинственное строгое требование для Управляемого ClickStack — данные должны включать столбец временной метки (или эквивалентное поле времени), который можно указать при настройке источника данных в интерфейсе ClickStack.
Создайте базу данных и таблицу
Для работы Vector перед ингестией данных необходимо заранее определить таблицу и схему.Сначала создайте базу данных. Это можно сделать через консоль ClickHouse Cloud.Например, создайте базу данных для логов:CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
Перейдите в интерфейс ClickStack
После завершения настройки ингестии и начала отправки данных выберите “Next”.Если вы настроили ингестию данных OpenTelemetry с помощью этого руководства, источники данных будут созданы автоматически, и дополнительная настройка не потребуется. Вы можете сразу приступить к работе с ClickStack. Вы будете перенаправлены в Search view, где источник будет выбран автоматически, чтобы вы могли сразу выполнять запросы.Вот и всё — всё готово 🎉.
Если вы настроили ингестию данных через Vector или другой источник, вам будет предложено настроить источник данных.Приведённая выше конфигурация предполагает схему в стиле Nginx со столбцом time_local, используемым в качестве временной метки. По возможности это должен быть столбец временной метки, объявленный в primary key. Этот столбец обязателен.Мы также рекомендуем обновить Default SELECT, чтобы явно указать, какие столбцы возвращаются в представлении журналов. Если доступны дополнительные поля, такие как Service name, log level или столбец body, их также можно настроить. Столбец для отображения временной метки тоже можно переопределить, если он отличается от столбца, используемого в primary key таблицы и настроенного выше.В приведённом выше примере столбец Body в данных отсутствует. Вместо этого он задаётся с помощью SQL-выражения, которое заново формирует строку журнала Nginx из доступных полей.О других возможных параметрах см. в справочнике по конфигурации.После настройки источника нажмите “Save” и приступайте к изучению своих данных.
- Перейдите к своему сервису в консоли ClickHouse Cloud
- Откройте Settings → SQL Console Access
- Установите подходящий уровень доступа для каждого пользователя:
- Service Admin → Full Access - Требуется для включения оповещений
- Service Read Only → Read Only - Может просматривать данные обсервабилити и создавать панели мониторинга
- No access - Не может получить доступ к HyperDX
Для оповещений требуется доступ администратораЧтобы включить оповещения, как минимум один пользователь с разрешениями Service Admin (сопоставленными с Full Access в раскрывающемся списке SQL Console Access) должен хотя бы один раз войти в HyperDX. Это создаст в базе данных выделенного пользователя, который будет выполнять запросы оповещений.
Использование ClickStack с вычислительными ресурсами в режиме только для чтения
Как ClickStack выбирает вычислительные ресурсы
- Если вы открываете ClickStack из сервиса только для чтения, все запросы, отправляемые из интерфейса ClickStack, будут выполняться на соответствующих ресурсах только для чтения.
- Если вы открываете ClickStack из сервиса с возможностью чтения и записи, ClickStack будет использовать соответствующие вычислительные ресурсы.
Для обеспечения режима только для чтения не требуется никакой дополнительной настройки в ClickStack.
Рекомендуемая конфигурация
- Создайте или выберите сервис ClickHouse Cloud в хранилище, настроенный в режиме только для чтения.
- В консоли ClickHouse Cloud выберите сервис только для чтения.
- Запустите ClickStack из меню навигации слева.
После запуска интерфейс ClickStack автоматически привяжется к этому сервису только для чтения.
Добавление дополнительных источников данных
Использование схем OpenTelemetry
Table значение otel_logs, чтобы создать источник логов. Все остальные настройки должны определиться автоматически, после чего вы сможете нажать Save New Source.
Чтобы создать источники для трассировок и OTel-метрик, выберите Create New Source в верхнем меню.
Здесь выберите нужный тип источника, а затем соответствующую таблицу; например, для трассировок выберите таблицу otel_traces. Все настройки должны определиться автоматически.
Коррелирование источниковОбратите внимание, что разные источники данных в ClickStack — например, логи и трассировки — можно коррелировать друг с другом. Для этого требуется дополнительная настройка каждого источника. Например, в источнике логов можно указать соответствующий источник трассировок, и наоборот — в источнике трассировок. Подробнее см. в разделе “Коррелированные источники”. Использование пользовательских схем
Выбор схемы: Map или JSON
Map(LowCardinality(String), String). Это рекомендуемая схема для рабочих нагрузок обсервабилити. В сочетании с сериализацией Map по бакетам и текстовыми индексами по ключам и значениям в Map она обеспечивает точечные lookup-операции без накладных расходов на приём для каждого ключа, характерных для динамических подстолбцов JSON.
Схема с типом JSON доступна в статусе бета для оценки на рабочих нагрузках с небольшим стабильным набором ключей атрибутов. Использовать её по умолчанию не рекомендуется. Полное сравнение и переменные окружения, необходимые для включения поддержки JSON, см. в разделе Map vs JSON type. Последнее изменение 10 июня 2026 г.