このガイドは既存の ClickHouse Cloud ユーザー向けです。ClickHouse Cloud を初めて利用する場合は、Managed ClickStack 向けの Getting Started ガイドを参照することをお勧めします。
このデプロイパターンでは、ClickHouse と ClickStack UI (HyperDX) の両方が ClickHouse Cloud でホストされるため、ユーザーがセルフホストする必要のあるコンポーネントを最小限に抑えられます。
このデプロイパターンでは、インフラストラクチャ管理の負担が軽減されるだけでなく、認証が ClickHouse Cloud の SSO/SAML と統合されることも保証されます。セルフホストのデプロイとは異なり、ダッシュボード、保存済み検索、ユーザー設定、アラートなどのアプリケーションの状態を保存するための MongoDB インスタンスを用意する必要もありません。さらに、ユーザーは次の利点も得られます。
- ストレージとは独立したコンピュートの自動スケーリング
- オブジェクトストレージに基づく低コストかつ実質的に無制限の保持
- Warehouses により、読み取りワークロードと書き込みワークロードを個別に分離できる
- 統合された認証
- 自動バックアップ
- セキュリティおよびコンプライアンス機能
- シームレスなアップグレード
このモードでは、データのインジェストは完全にユーザー側で行います。独自にホストした OpenTelemetry Collector、クライアントライブラリからの直接インジェスト、ClickHouse ネイティブのテーブルエンジン (Kafka や S3 など) 、ETL パイプライン、または ClickHouse Cloud のマネージドインジェストサービスである ClickPipes を使用して、Managed ClickStack にデータを取り込むことができます。この方法は、ClickStack を運用するうえで最もシンプルかつ高性能なアプローチです。
このデプロイパターンは、次のようなケースに適しています。
- すでに ClickHouse Cloud にオブザーバビリティデータがあり、ClickStack を使って可視化したい場合。
- 大規模なオブザーバビリティ環境を運用しており、ClickHouse Cloud 上で動作する ClickStack の専用のパフォーマンスとスケーラビリティが必要な場合。
- すでに分析用途で ClickHouse Cloud を利用しており、ClickStack のインストルメンテーションライブラリを使ってアプリケーションをインストルメントし、同じクラスターにデータを送信したい場合。この場合は、オブザーバビリティワークロード用のコンピュートを分離するため、warehouses の使用を推奨します。
以下のガイドは、すでに ClickHouse Cloud サービスを作成済みであることを前提としています。まだサービスを作成していない場合は、Managed ClickStack の Getting Started ガイドに従ってください。これにより、このガイドと同じ状態、つまり ClickStack が有効になっており、オブザーバビリティデータを受け入れられる状態のサービスが用意されます。
新しいサービスを作成する
ClickHouse Cloud のランディングページで New service を選択し、新しいサービスを作成します。プロバイダー、リージョン、リソースを指定する
Scale と Enterpriseほとんどの ClickStack ワークロードには、この Scale tier を推奨します。SAML、CMEK、HIPAA 準拠などの高度なセキュリティ機能が必要な場合は、Enterprise tier を選択してください。また、非常に大規模な ClickStack デプロイメント向けにカスタムのハードウェアプロファイルも利用できます。このような場合は、サポートにお問い合わせいただくことをお勧めします。 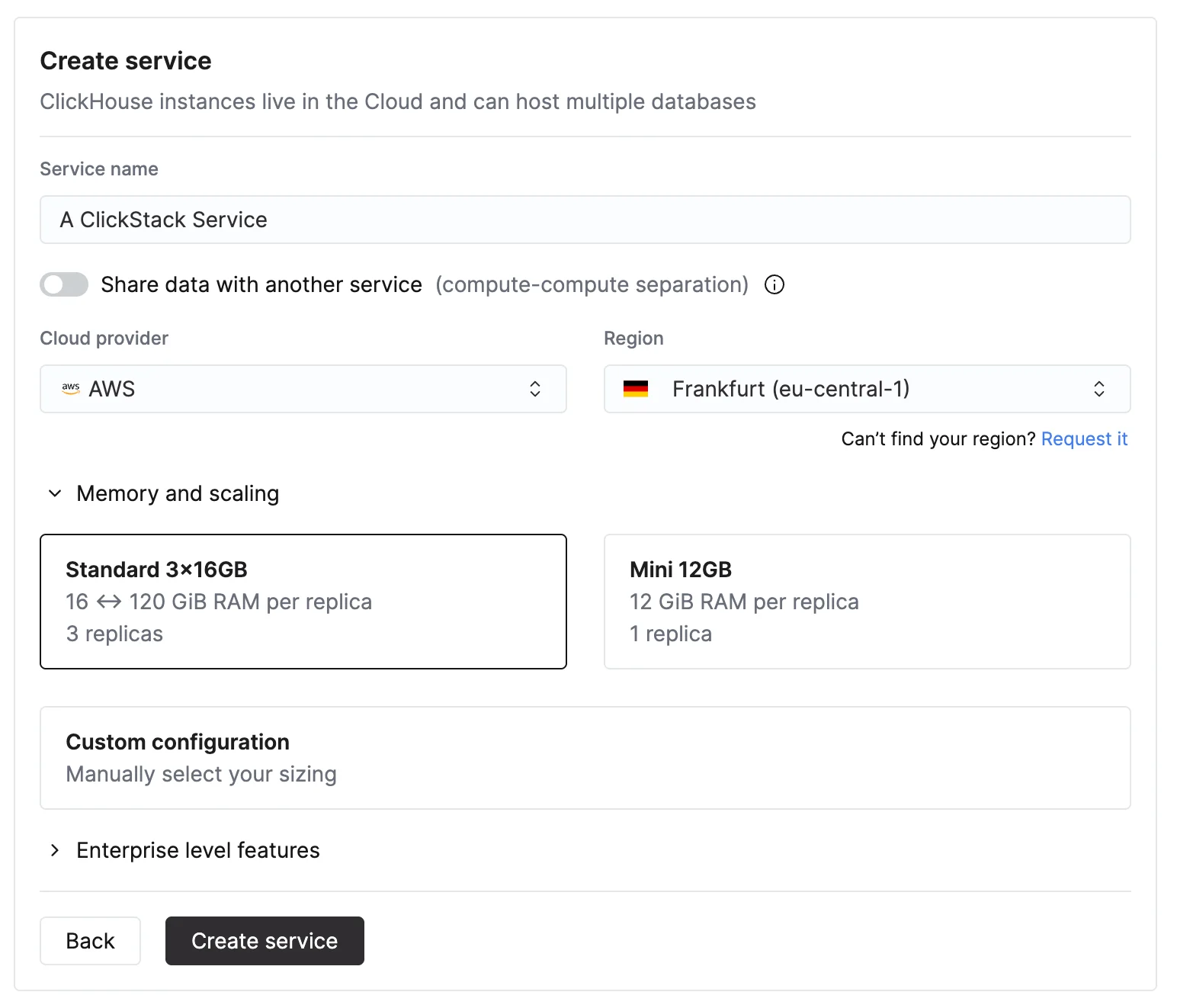 CPU とメモリを選択する際は、想定される ClickStack のインジェストスループットに基づいて見積もってください。以下の表は、これらのリソースをサイジングする際の目安です。
CPU とメモリを選択する際は、想定される ClickStack のインジェストスループットに基づいて見積もってください。以下の表は、これらのリソースをサイジングする際の目安です。| Monthly ingest volume | Recommended compute |
|---|
| < 10 TB / month | 2 vCPU × 3 replicas |
| 10–50 TB / month | 4 vCPU × 3 replicas |
| 50–100 TB / month | 8 vCPU × 3 replicas |
| 100–500 TB / month | 30 vCPU × 3 replicas |
| 1 PB+ / month | 59 vCPU × 3 replicas |
- データ量は、月あたりの非圧縮インジェスト量を指し、ログとトレースの両方に適用されます。
- クエリパターンは、オブザーバビリティの一般的なユースケースを想定しており、ほとんどのクエリは直近のデータ、通常は過去 24 時間を対象とします。
- インジェストは月全体を通して比較的均一であると想定しています。突発的なトラフィックやスパイクが見込まれる場合は、追加の余裕を持ってプロビジョニングしてください。
- ストレージは ClickHouse Cloud のオブジェクトストレージで別途処理されるため、保持期間の制約要因にはなりません。長期間保持されるデータは、アクセス頻度が低いことを前提としています。
より長い時間範囲を定期的にクエリするアクセスパターン、負荷の高い集計処理、または多数の同時利用ユーザーをサポートする場合は、さらに多くのコンピュートが必要になることがあります。特定のインジェストスループットに必要な CPU とメモリは 2 つのレプリカでも満たせますが、可能であれば、総容量を同等に保ちながらサービスの冗長性を高めるために 3 つのレプリカを使用することを推奨します。これらの値はあくまで推定値であり、初期ベースラインとして使用してください。実際に必要なリソースは、クエリの複雑さ、同時実行性、保持ポリシー、インジェストスループットのばらつきによって異なります。常にリソース使用状況を監視し、必要に応じてスケールしてください。
インジェストを設定する
サービスのプロビジョニングが完了したら、そのサービスが選択されていることを確認し、左側のメニューで “ClickStack” をクリックします。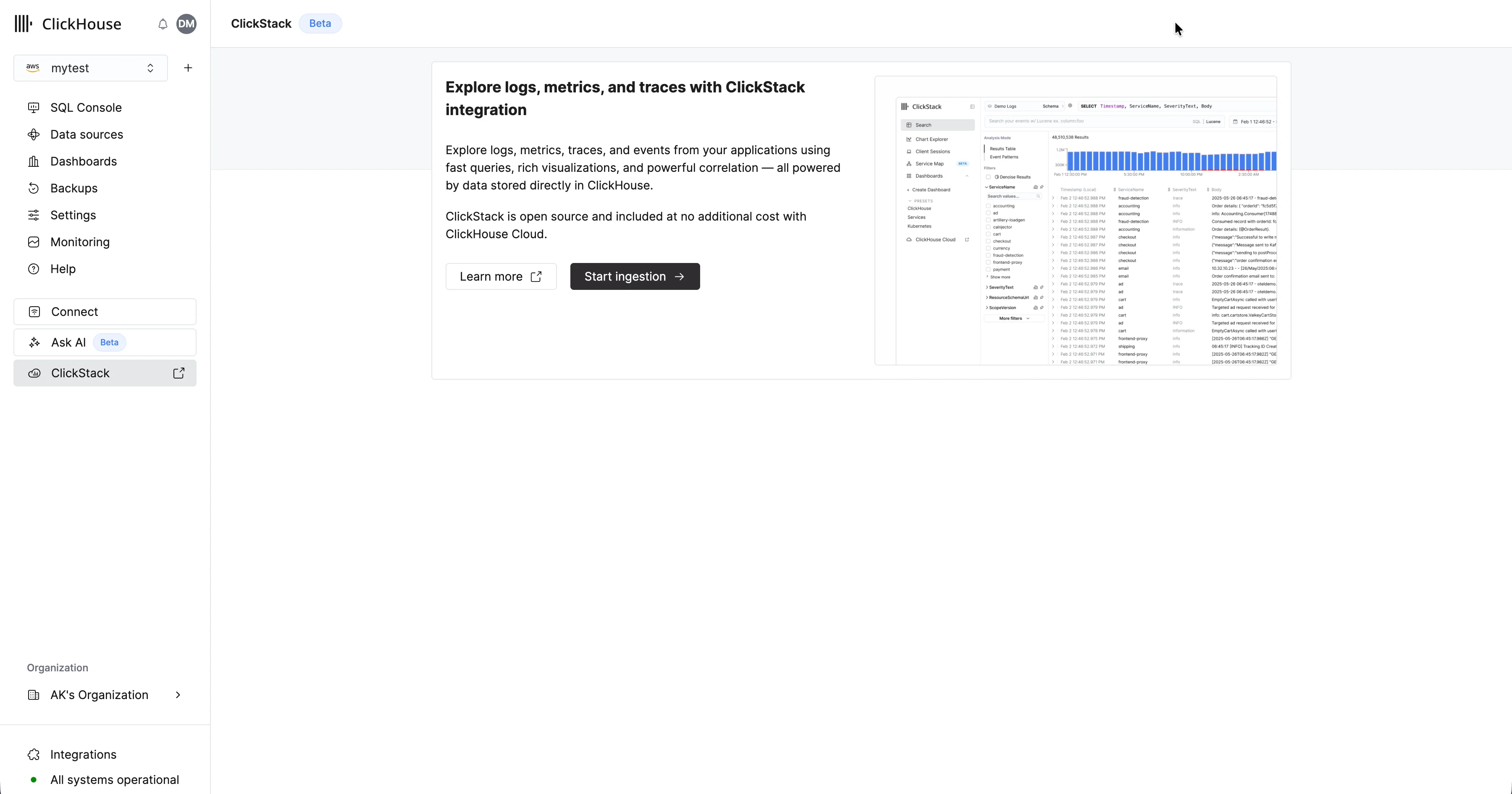 「Start Ingestion」を選択すると、インジェストソースを選択するよう求められます。Managed ClickStack では、主要なインジェストソースとして OpenTelemetry と Vector をサポートしています。一方で、ユーザーは ClickHouse Cloud でサポートされているインテグレーション のいずれかを使用して、独自のスキーマでデータを ClickHouse に直接送信することもできます。
「Start Ingestion」を選択すると、インジェストソースを選択するよう求められます。Managed ClickStack では、主要なインジェストソースとして OpenTelemetry と Vector をサポートしています。一方で、ユーザーは ClickHouse Cloud でサポートされているインテグレーション のいずれかを使用して、独自のスキーマでデータを ClickHouse に直接送信することもできます。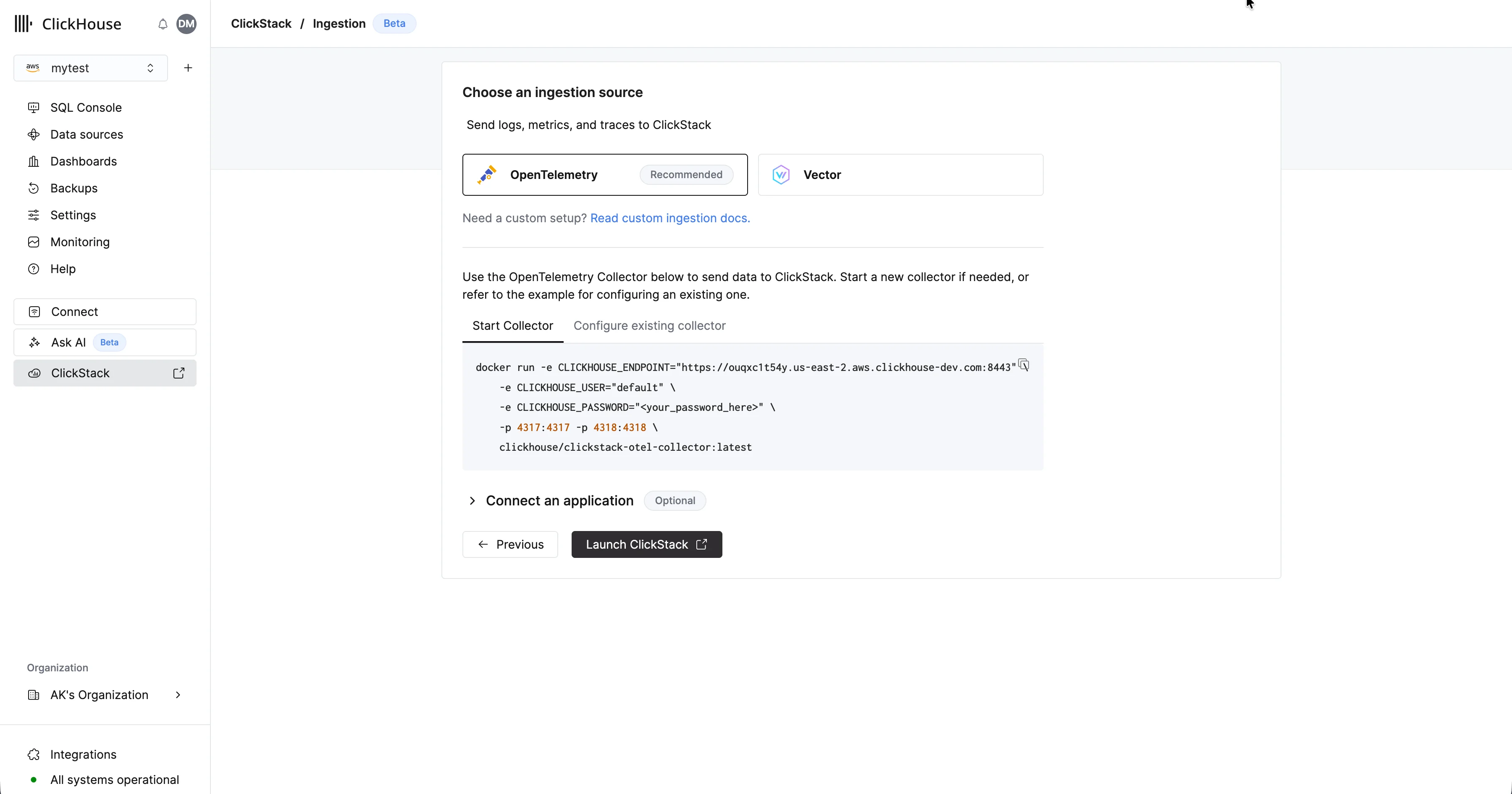
OpenTelemetry を推奨インジェスト形式としては、OpenTelemetry の使用を強く推奨します。
ClickStack で効率的に動作するよう特別に設計された、すぐに使えるスキーマが用意されており、最もシンプルかつ最適化された利用体験を提供します。
Managed ClickStack に OpenTelemetry データを送信するには、OpenTelemetry Collector を使用することを推奨します。collector は、アプリケーション (および他の collector) から OpenTelemetry データを受信し、ClickHouse Cloud に転送するゲートウェイとして機能します。まだ collector を実行していない場合は、以下の手順で起動してください。既存の collector がある場合は、設定例も用意されています。collector を起動する
以下では、追加の処理を含み、ClickHouse Cloud 向けに最適化された、推奨構成である ClickStack distribution of the OpenTelemetry Collector を使用することを前提としています。独自の OpenTelemetry Collector を使用する場合は、“既存の collector を設定する。” を参照してください。すぐに開始するには、表示されている Docker コマンドをコピーして実行してください。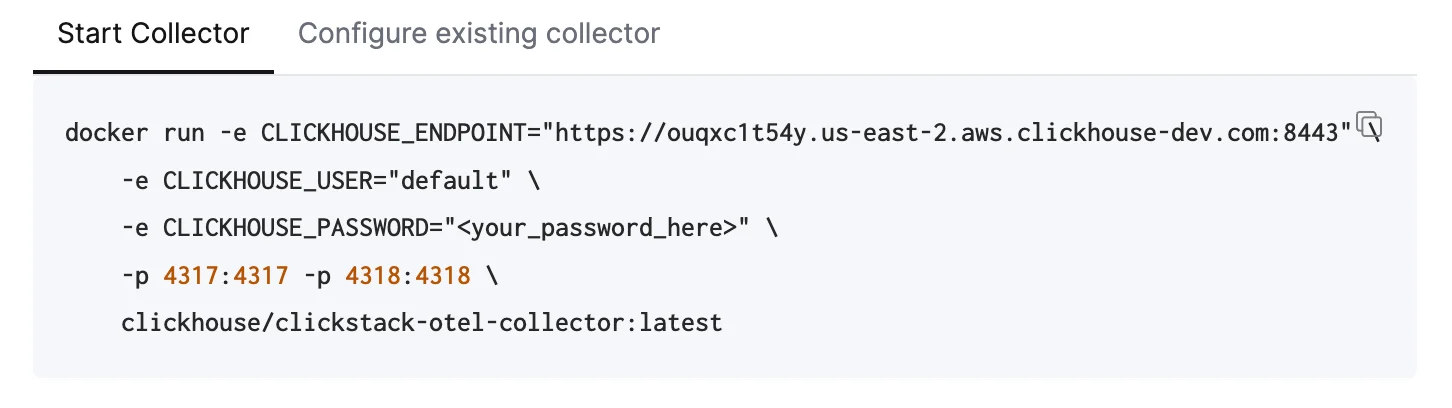 このコマンドには、接続 credentials があらかじめ入力されています。
このコマンドには、接続 credentials があらかじめ入力されています。本番環境へのデプロイこのコマンドでは Managed ClickStack への接続に default ユーザーを使用していますが、本番環境に移行する 際は、専用ユーザーを作成し、設定を変更する必要があります。 既存の collector を設定する
既存の OpenTelemetry Collectors を設定したり、独自の distribution の collector を使用したりすることも可能です。この用途のために、適切な設定で ClickHouse exporter を使用し、OTLP receiver を公開する OpenTelemetry Collector の設定例が提供されています。この設定は、ClickStack distribution で想定されているインターフェイスと動作に合わせています。OpenTelemetry collector の設定について詳しくは、“OpenTelemetry でインジェストする。” を参照してください。インジェストを開始する (任意)
OpenTelemetry でインストルメントする既存のアプリケーションやインフラストラクチャがある場合は、UI からリンクされている該当ガイドに進んでください。traces と logs を収集するようアプリケーションをインストルメントするには、サポートされている言語 SDKs を使用してください。これらは、Managed ClickStack へのインジェスト用ゲートウェイとして動作する OpenTelemetry Collector にデータを送信します。logs は、agent モードで実行され、同じ collector にデータを転送する OpenTelemetry Collectors を使用して収集 できます。Kubernetes の監視については、専用ガイド を参照してください。その他のインテグレーションについては、quickstart ガイド を参照してください。デモデータ
既存のデータがない場合は、サンプル dataset のいずれかを試すこともできます。 Vector は、高性能でベンダー中立なオブザーバビリティデータパイプラインであり、特にその柔軟性と少ないリソース消費から、ログのインジェストで広く利用されています。ClickStack で Vector を使用する場合、ユーザーは独自のスキーマを定義する必要があります。これらのスキーマは OpenTelemetry の規約に従うこともできますが、ユーザー定義のイベント構造を表す完全にカスタムなものにすることもできます。Timestamp は必須Managed ClickStack で唯一の必須要件は、データに timestamp カラム (または同等の時刻フィールド) が含まれていることです。これは ClickStack UI でログソースを設定する際に指定できます。
データベースとテーブルを作成する
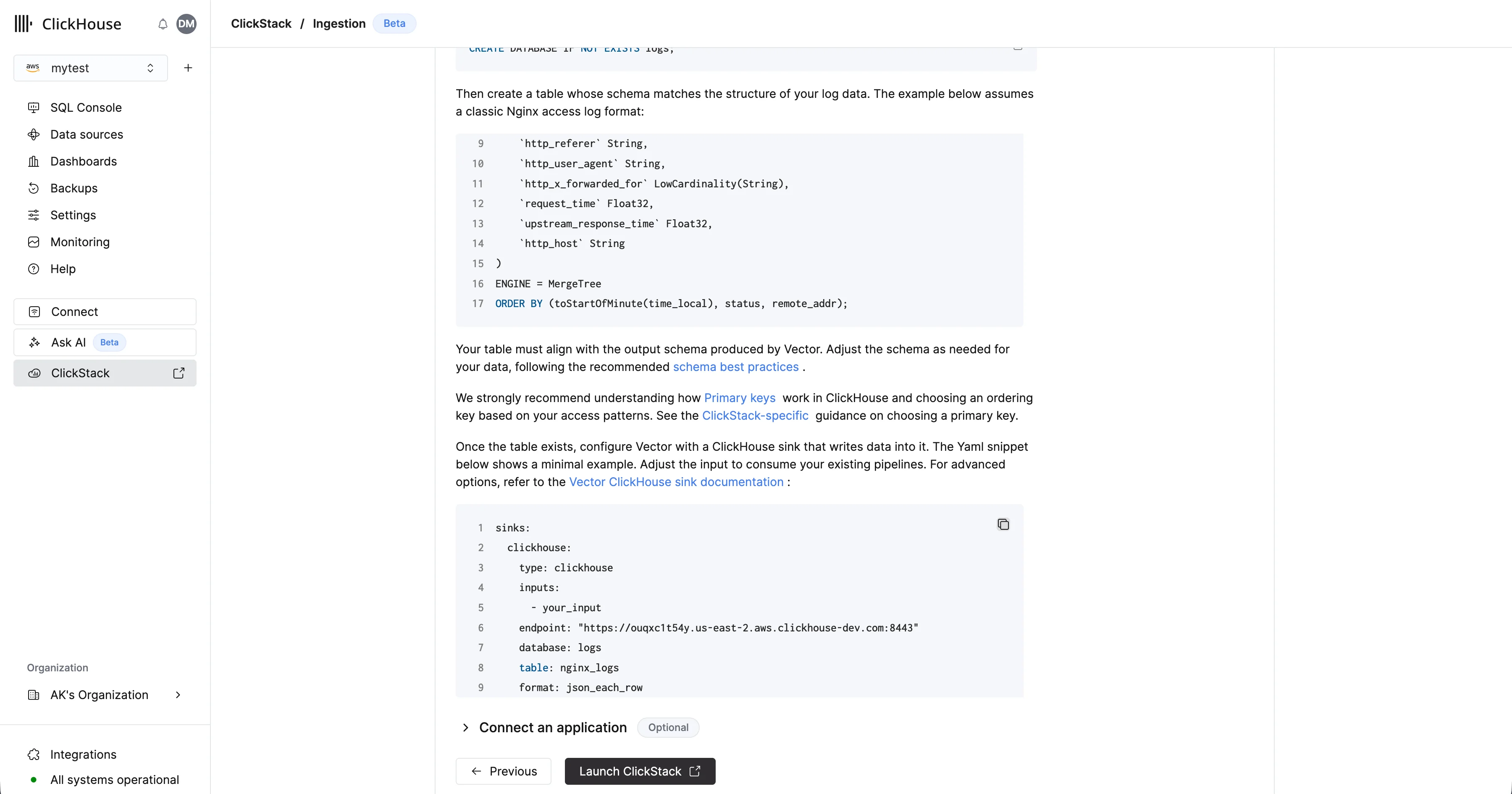
Vector では、データを取り込む前にテーブルとスキーマを定義しておく必要があります。まず、データベースを作成します。これは ClickHouse Cloud console から実行できます。たとえば、ログ用のデータベースを作成します。CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
 Vector を使ったデータ取り込みのその他の例については、“Vector で取り込む”または高度なオプションについては Vector ClickHouse sink documentation を参照してください。
Vector を使ったデータ取り込みのその他の例については、“Vector で取り込む”または高度なオプションについては Vector ClickHouse sink documentation を参照してください。 サービスを選択
ClickHouse Cloud のランディングページで、Managed ClickStack を有効にする対象のサービスを選択します。リソースの見積もりこのガイドでは、ClickStack で取り込みおよびクエリする予定のオブザーバビリティデータ量を処理できる十分なリソースが、あらかじめプロビジョニングされていることを前提としています。必要なリソースを見積もるには、Estimating Resources ガイドを参照してください。ClickHouse サービスが、リアルタイムのアプリケーション分析などの既存のワークロードをすでにホストしている場合は、オブザーバビリティのワークロードを分離するために、ClickHouse Cloud’s warehouses feature を使用して子サービスを作成することをおすすめします。これにより、既存のアプリケーションに影響を与えることなく、両方のサービスからデータセットにアクセスできる状態を維持できます。 ClickStack UI に移動する
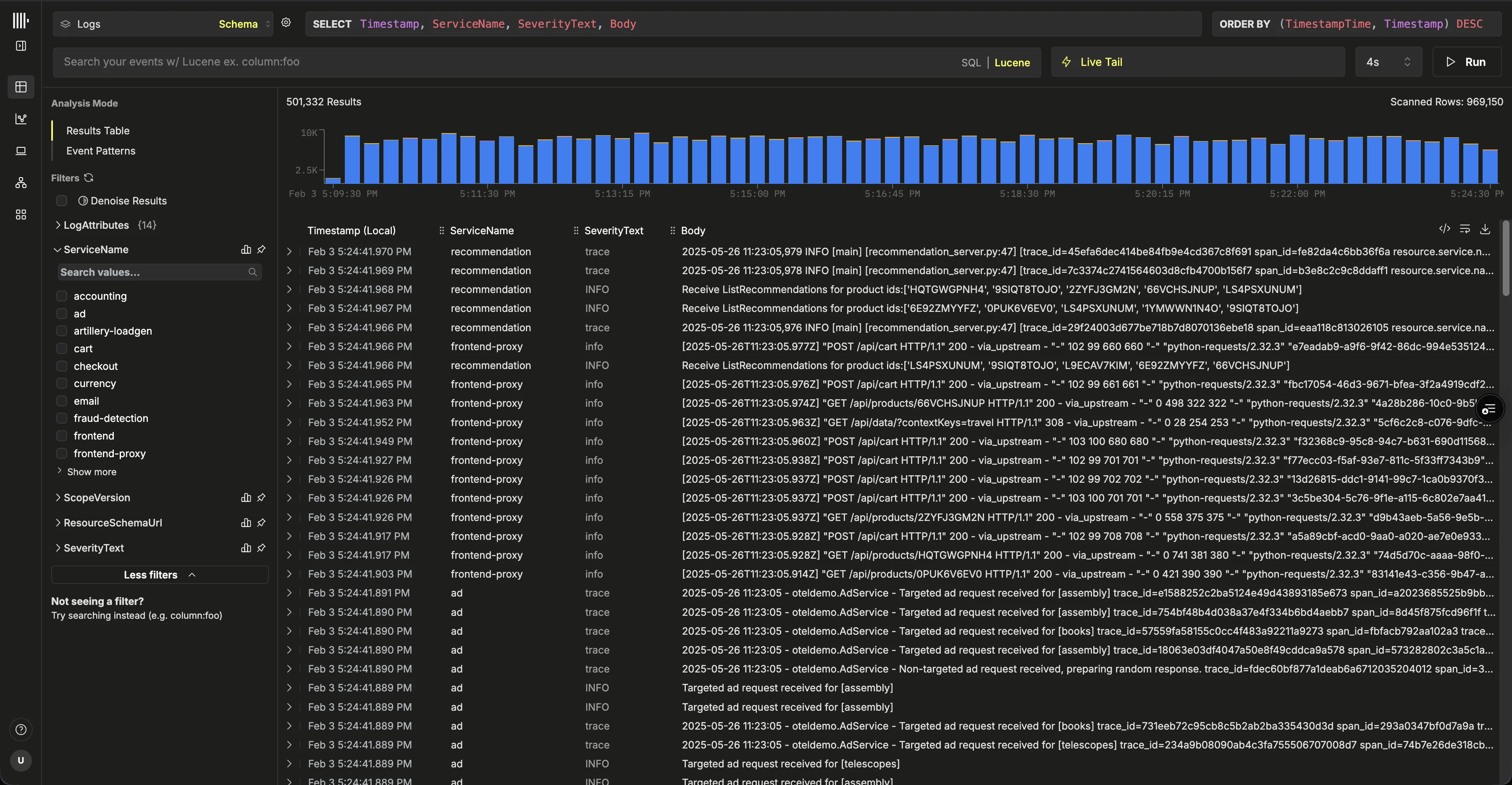
左側のナビゲーションメニューから ‘ClickStack’ を選択します。ClickStack UI にリダイレクトされ、ClickHouse Cloud の権限に基づいて自動的に認証されます。サービスに OpenTelemetry テーブルがすでに存在する場合、それらは自動検出され、対応するデータソースが作成されます。データソースの自動検出自動検出は、ClickStack ディストリビューションの OpenTelemetry collector が提供する標準の OpenTelemetry テーブルスキーマに基づいて行われます。最も完全なテーブルセットを持つデータベースに対してログソースが作成されます。必要に応じて、追加のテーブルは個別のデータソースとして追加できます。 インジェストの設定
自動検出に失敗した場合、または既存のテーブルがない場合は、インジェストのセットアップを行うよう求められます。“Start Ingestion”を選択すると、インジェストソースの選択画面が表示されます。Managed ClickStackは、主要なインジェストソースとしてOpenTelemetryおよびVectorをサポートしています。また、ClickHouse Cloudがサポートするインテグレーションを使用して、独自のスキーマでClickHouseに直接データを送信することもできます。OpenTelemetry を推奨インジェスト用フォーマットとして、OpenTelemetry の使用を強く推奨します。
ClickStack で効率的に動作するよう設計された、すぐに使えるスキーマが用意されているため、最もシンプルかつ最適化された形で利用できます。
Managed ClickStack に OpenTelemetry データを送信するには、OpenTelemetry Collector の使用を推奨します。collector は、アプリケーション (および他の collector) から OpenTelemetry データを受信し、それを ClickHouse Cloud に転送するゲートウェイとして機能します。まだ collector を稼働させていない場合は、以下の手順に従って起動してください。既存の collector がある場合は、そのための configuration 例も用意されています。collector を起動する
以下では、推奨される方法である ClickStack distribution of the OpenTelemetry Collector の使用を前提としています。これには追加の processing が含まれており、ClickHouse Cloud 向けに最適化されています。独自の OpenTelemetry Collector を使用したい場合は、「既存の collector を設定する」 を参照してください。すばやく始めるには、表示されている Docker コマンドをコピーして実行してください。このコマンドは、service の作成時に記録した service credentials に合わせて変更してください。production へのデプロイこのコマンドでは Managed ClickStack への接続に default ユーザーを使用していますが、production に移行する 際は、専用ユーザーを作成し、configuration を変更してください。 既存の collector を設定する
既存の OpenTelemetry Collectors を設定することも、独自の collector distribution を使用することもできます。この目的のために、適切な設定で ClickHouse exporter を使用し、OTLP receiver を公開する OpenTelemetry Collector configuration の例が用意されています。この configuration は、ClickStack distribution で想定されるインターフェイスと動作に一致しています。以下にこの構成の例を示します (UIからコピーする場合、環境変数はあらかじめ入力された状態になります) :receivers:
otlp/hyperdx:
protocols:
grpc:
include_metadata: true
endpoint: "0.0.0.0:4317"
http:
cors:
allowed_origins: ["*"]
allowed_headers: ["*"]
include_metadata: true
endpoint: "0.0.0.0:4318"
processors:
batch:
memory_limiter:
# 最大メモリの80%(上限2G)。メモリが少ない環境では調整してください
limit_mib: 1500
# 上限の25%(上限2G)。メモリが少ない環境では調整してください
spike_limit_mib: 512
check_interval: 5s
connectors:
routing/logs:
default_pipelines: [logs/out-default]
error_mode: ignore
table:
- context: log
statement: route() where IsMatch(attributes["rr-web.event"], ".*")
pipelines: [logs/out-rrweb]
exporters:
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
clickhouse/rrweb:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
logs_table_name: hyperdx_sessions
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
clickhouse:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
traces:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
metrics:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/in:
receivers: [otlp/hyperdx]
exporters: [routing/logs]
logs/out-default:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/out-rrweb:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse/rrweb]
インジェストを開始する (任意)
OpenTelemetry でインストルメントする既存のアプリケーションやインフラストラクチャがある場合は、「Connect an application」からリンクされている関連ガイドに進んでください。アプリケーションをインストルメントして traces と logs を収集するには、サポートされている language SDKs を使用してください。これらは、Managed ClickStack へインジェストするためのゲートウェイとして機能する OpenTelemetry Collector にデータを送信します。logs は、agent モードで実行される OpenTelemetry Collectors を使用して収集 し、同じ collector に転送できます。Kubernetes の監視については、専用ガイド を参照してください。その他のインテグレーションについては、quickstart ガイド を参照してください。 Vector は、高性能でベンダーに依存しないオブザーバビリティ向けデータパイプラインであり、特にその柔軟性とリソース使用量の少なさから、ログのインジェストで広く利用されています。Vector を ClickStack と併用する場合、スキーマはユーザー自身で定義する必要があります。これらのスキーマは OpenTelemetry の規約に従うこともできますが、ユーザー定義のイベント構造を表す完全にカスタムなものにすることも可能です。timestamp が必要ですManaged ClickStack における唯一の厳密な要件は、データに timestamp カラム (または同等の時刻フィールド) が含まれていることです。これは、ClickStack UI でデータソースを設定する際に指定できます。
データベースとテーブルを作成する
Vector では、データの取り込み前にテーブルとスキーマを定義しておく必要があります。まず、データベースを作成します。これは ClickHouse Cloud console から実行できます。たとえば、ログ用のデータベースを作成します。CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
ClickStack UI に移動する
インジェストの設定を完了し、データの送信を開始したら、“Next” を選択します。このガイドを使用して OpenTelemetry データを取り込んだ場合、データソースは自動的に作成されるため、追加の設定は不要です。すぐに ClickStack を使い始められます。ログソースが自動的に選択された検索ビューに移動するので、すぐにクエリを開始できます。これで完了です。準備はすべて整いました 🎉。
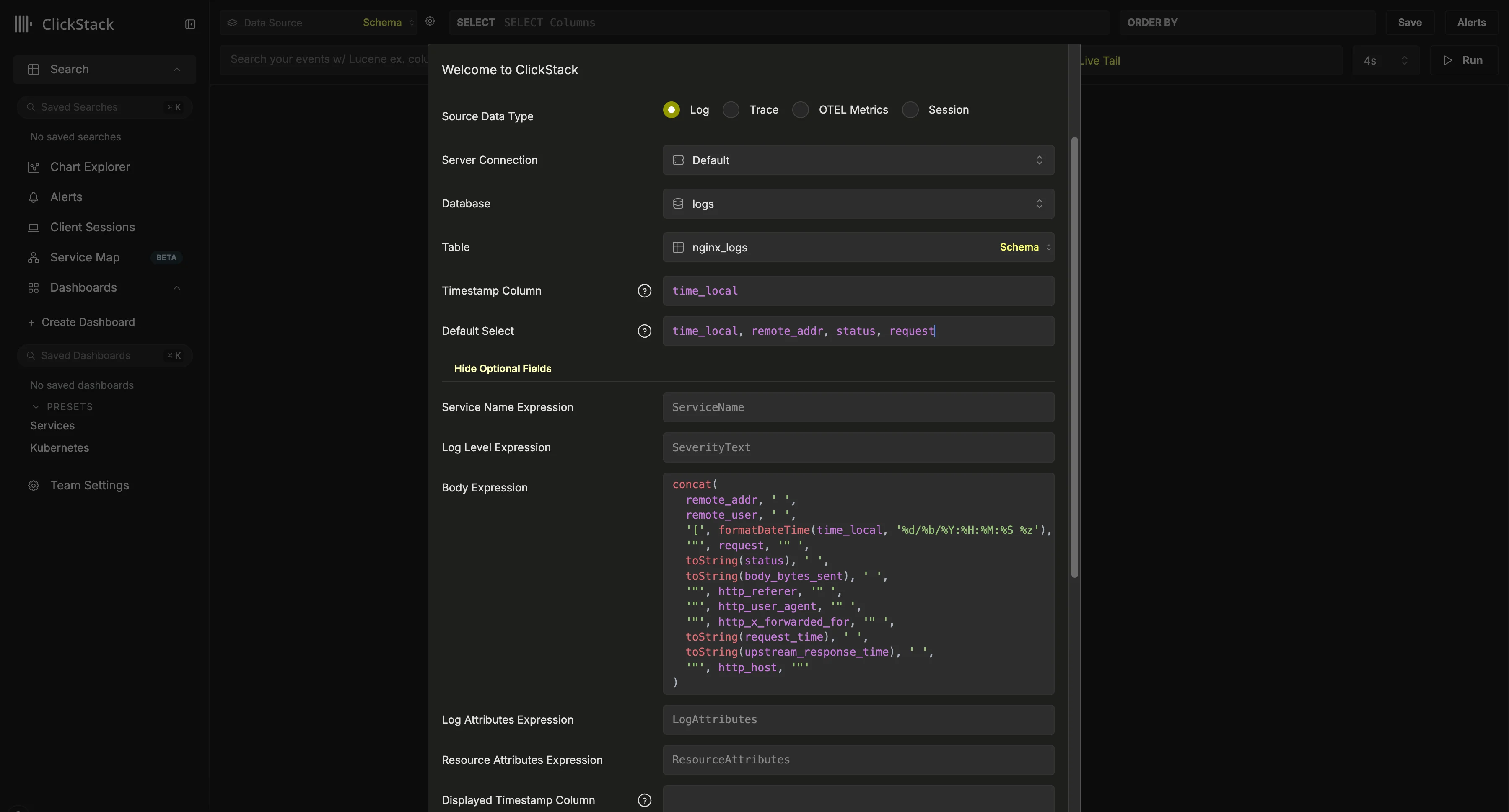
Vector やその他のソース経由でデータを取り込んだ場合は、データソースを設定するよう求められます。上記の設定は、タイムスタンプとして time_local カラムを使用する Nginx 形式のスキーマを前提としています。可能であれば、ここには主キーで定義されているタイムスタンプカラムを指定してください。このカラムは必須です。また、ログビューで返されるカラムを明示的に定義するため、Default SELECT を更新することをおすすめします。サービス名、ログレベル、ボディカラムなどの追加フィールドがある場合は、それらも設定できます。タイムスタンプの表示カラムが、テーブルの主キーで使用されているカラムや上記で設定したカラムと異なる場合は、それも上書きできます。上記の例では、データ内に Body カラムは存在しません。代わりに、利用可能なフィールドから Nginx のログ行を再構築する SQL 式を使って定義されています。その他のオプションについては、設定リファレンス を参照してください。ログソースを設定したら、“Save” をクリックしてデータの確認を開始します。
- ClickHouse Cloud コンソールで対象のサービスに移動します
- Settings → SQL Console Access に進みます
- 各ユーザーに適切な権限レベルを設定します:
- Service Admin → Full Access - アラートを有効にするために必要です
- Service Read Only → Read Only - オブザーバビリティデータを表示し、ダッシュボードを作成できます
- No access - HyperDX にアクセスできません
アラートには管理者アクセスが必要ですアラートを有効にするには、Service Admin 権限を持つユーザー (SQL Console Access のドロップダウンでは Full Access に対応) が少なくとも 1 回 HyperDX にログインする必要があります。これにより、アラートクエリを実行する専用ユーザーがデータベース内に作成されます。
読み取り専用コンピュートで ClickStack を使用する
ClickStack がコンピュートを選択する仕組み
- 読み取り専用サービス から ClickStack を開いた場合、ClickStack UI が発行するすべての queries は、その read-only コンピュートで実行されます。
- read-write service から ClickStack を開いた場合は、ClickStack は代わりにそのコンピュートを使用します。
read-only の動作を実現するために、ClickStack 内で追加の configuration を行う必要はありません。
読み取り専用のコンピュートで ClickStack を実行するには、次の手順に従います。
- 読み取り専用として構成された warehouse 内で、ClickHouse Cloud サービスを作成するか、既存のサービスを選択します。
- ClickHouse Cloud コンソールで、読み取り専用のサービスを選択します。
- 左側のナビゲーションメニューから ClickStack を起動します。
起動後、ClickStack UI は自動的にこの読み取り専用サービスに紐付けられます。
ClickStack は OpenTelemetry をネイティブでサポートしていますが、OpenTelemetry に限定されません。必要に応じて、独自のテーブルスキーマも使用できます。
以下では、自動的に設定されるもの以外に、追加のデータソースをユーザーが追加する方法を説明します。
OTel collector を使用して ClickHouse 内にデータベースとテーブルを作成している場合は、ソース作成フォームですべてのデフォルト値をそのまま使用し、ログソースを作成するために Table フィールドに otel_logs を入力します。その他の設定はすべて自動検出されるため、Save New Source をクリックできます。
traces と OTel メトリクスのソースを作成するには、上部メニューから 新しいソースを作成 を選択します。
ここでは、必要なソースタイプを選択してから、適切なテーブルを選択します。たとえば traces の場合は、otel_traces テーブルを選択します。すべての設定は自動検出されます。
ソースの相関付けClickStack 内の異なるデータソース (logs や traces など) は、相互に相関付けることができます。これを有効にするには、各ソースで追加の設定が必要です。たとえば、ログソースでは対応するトレースソースを指定でき、traces ソースではその逆に対応するログソースを指定できます。詳しくは、「相関ソース」を参照してください。 Map(LowCardinality(String), String) カラムとして保存します。これは、オブザーバビリティのワークロードに推奨されるスキーマです。bucketed map serialization と、Map のキーおよび値に対するテキスト索引を組み合わせることで、動的な JSON サブカラムのようにキーごとの取り込みオーバーヘッドを発生させることなく、必要なルックアップだけを効率的に実行できます。
JSON 型のスキーマは、属性キーの集合が小さく安定しているワークロードで評価するためのベータ機能として利用できます。これはデフォルトとしては推奨されません。詳しい比較と、JSON サポートを有効にするために必要な環境変数については、Map と JSON 型の比較 を参照してください。